First of all is to be able to use INT8 model example of a substantial increase in performance MoiblenetV2
https://github.com/tensorflow/models/tree/master/research/slim/nets/mobilenet to download from here to download model mobilenet_v2_1. 4 _224 this model, and then converted into OpenVINO FP32 model
Python "c: \ Program Files \ IntelSWTools \ openvino \ (x86) deployment_tools \ model_optimizer \ mo_tf py" - reverse_input_channels - input_shape=[1224224] - input=input - mean_values=input [127.5, 127.5, 127.5] - scale_values=input [127.5], the output=MobilenetV2/Predictions/Reshape_1 -- input_model=mobilenet_v2_1. 4 _224_frozen. Pb
When mo conversion, specifies the scheme/shift and reverse_input_channel, let OpenVINO help when inference to switch the input pixels for RGB BGR, and normalization between [1, 1]
By observation of netron original mobilenet_v2_1. 4 _224_frozen. Pb network architecture and the transformed mobilenet_v2_1. 4 _224_frozen. XML network architecture
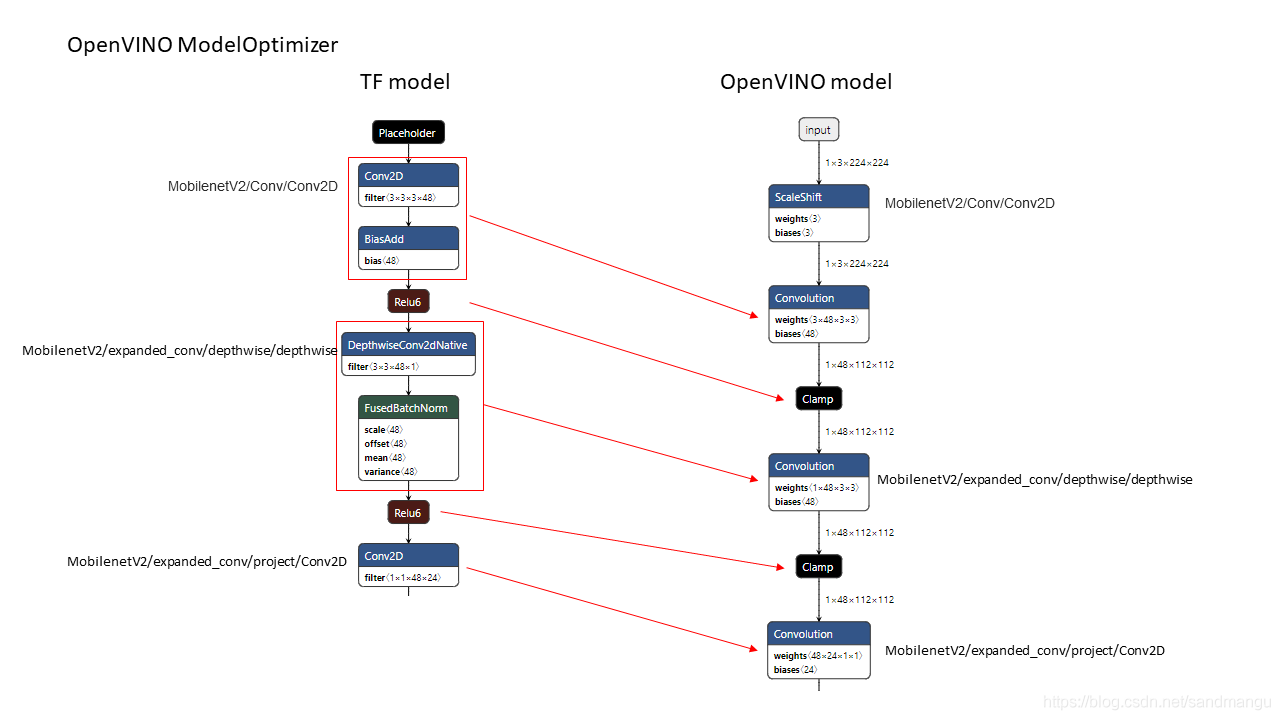
Look at the input layer under the layers of the network, you can see MO at the time of conversion combine Conv2D and BiasAdd optimization has become a Convolution operation, combine DepthwiseConv2D and FusedBN became a Convolution operation, through the network layer of the merger, saves multiple network layer between the input and output of memory read/write bandwidth costs, very good:)
Then look at run time, IE use openvino SDK own benchmark app
Benchmark_app. Exe - m mobilenet_v2_1. 4 _224_frozen. XML - nireq nstreams - 1 - b - 1 PC
Here just want to get the fastest time, single frame image of reasoning does not consider high concurrency, so the above parameter specifies each inference request only 1, sync - API can also be used to obtain the same data
Benchmark_app. Exe - m mobilenet_v2_1. 4 _224_frozen. XML API sync - PC
- PC parameters can make the benchmark after print out each layer of network computing time, and then watched a head a few layers of operation time
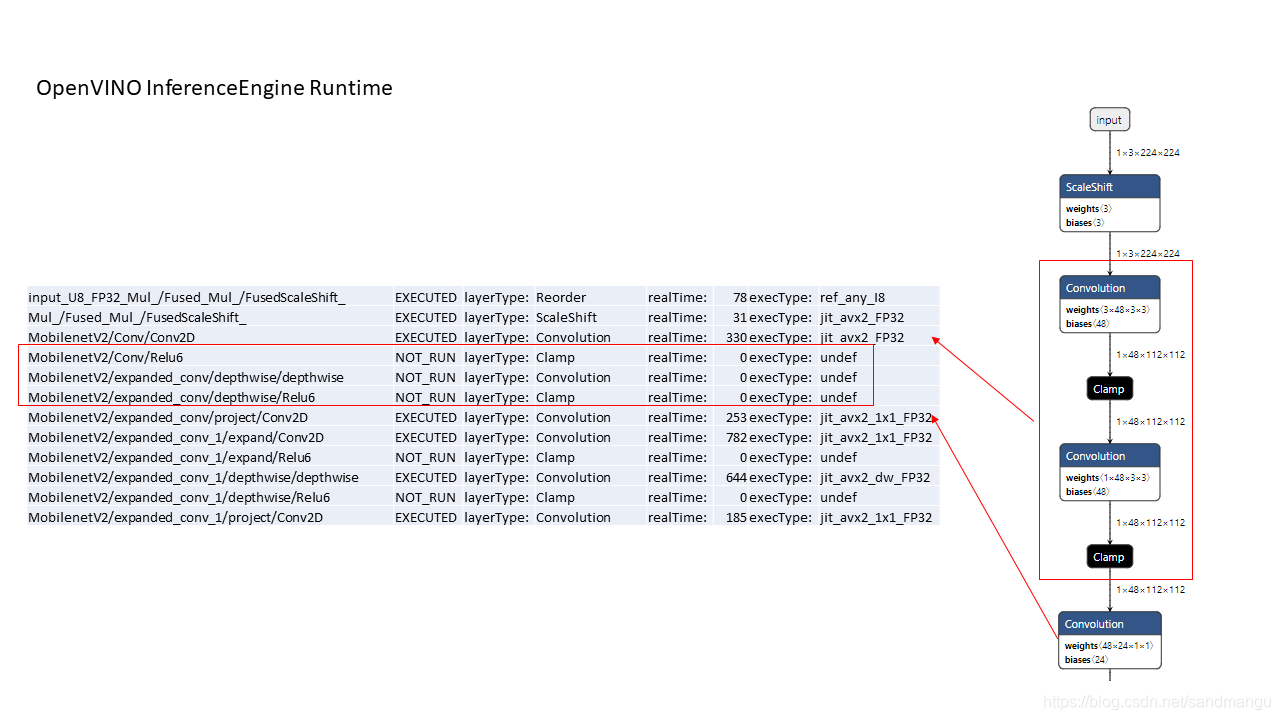
IE at the time of operation, through the MKL - within DNN post - ops operation, the convolution - & gt; Relu6 - & gt; Depthwise_convolution - & gt; Relu6 4 layers and merge together to calculate the operation, the cost and saving a lot of memory, speaking, reading and writing under the,
In the end we got MobilenetV2 FP32 calculation time of each layer each inference 7.75 ms
Full device name: Intel (R) Core (TM) hq @ 2.80 GHz CPU i5-7440
Count: 6688 iterations
Duration: 60023.43 ms
Latency: 7.75 ms
Throughput: 111.42 FPS
Then look at INT8 model running time
First converts INT8 model, model transformation is the simplest method is to use OpenVINO official docker workbench to transform, all graphical operation, saves the writing time of different transformation configuration file; Another method is to use the SDK's own calibration tool tools to transform, if not consider conversion accuracy, you can set the conversion mode for sm (simple mode), in this mode, do not need to provide the sample set is used to calculate conversion precision, conversion tool will convert all can be transformed into INT8 network layer, it turns out the model while the accuracy loss is very big, but can use benchmark_app to rapid assessment translate INT8 model performance improvement,
Python "c: \ Program Files \ IntelSWTools \ openvino \ (x86) deployment_tools \ tools \ calibration_tool \ calibrate py" - sm - m mobilenet_v2_1. 4 _224_frozen. XML - e - c: \ Users \??? \ Documents \ Intel \ OpenVINO \ inference_engine_samples_build \ intel64 \ Release \ cpu_extension DLL
Conversion of INT8 model can continue to use benchmark print out the computation time of each layer, and time to do a comparison and FP32
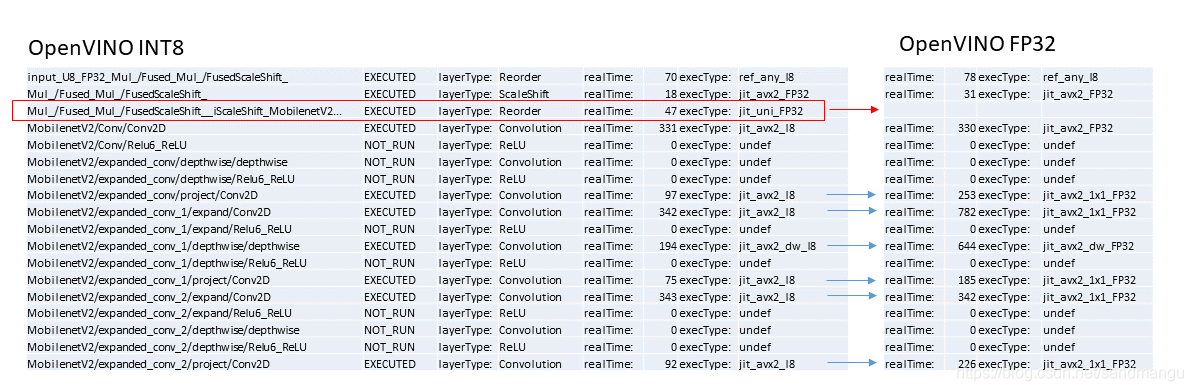
You can see
INT8 model in Conv INT8 calculation before, do a step more FP32, because MKL - within DNN Conv FP32 computation, the most efficient memory format is nChw8c, and Conv INT8 calculation, the preferred format is NHWC memory, so the switch from FP32 calculation to the front of the INT8 mode, to do first step the Reorder; In the same way before INT8 calculation after return FP32 calculation, also need to do more step the Reorder, arrange memory data conversion back again,
Every time relative to the Conv FP32, Conv INT8 convolution computation time can be greatly reduced, my highest CPU support to AVX2, if the CPU supports AVX512, the computing time can continue to shrink,
Overall INT8 model reasoning time is 4.70 ms per frame, promoted many relatively FP32 reasoning 7.75 ms
Full device name: Intel (R) Core (TM) hq @ 2.80 GHz CPU i5-7440
Count: 12037 iterations
Duration: 60006.28 ms
Latency: 4.70 ms
Throughput: 200.60 FPS
Note that the above 4.70 ms is only a theoretical data, the data is the premise of all to be able to switch to INT8 convolution calculation into INT8 calculation, in the process of actual transformation, calibration tool will be according to your defined accuracy loss threshold to dynamically adjust the conversion of Conv layer number, if the accuracy loss more than your threshold, will put some Conv INT8 convolution back to FP32 convolution layer, the resulting INT8 model can have both INT8 convolution layer, also can have FP32 convolution layer, so will the actual performance than the theoretical value,
In the end, the statistics of the MobilenetV2 FP32 and INT8 reasoning when the number of layers and CPU time
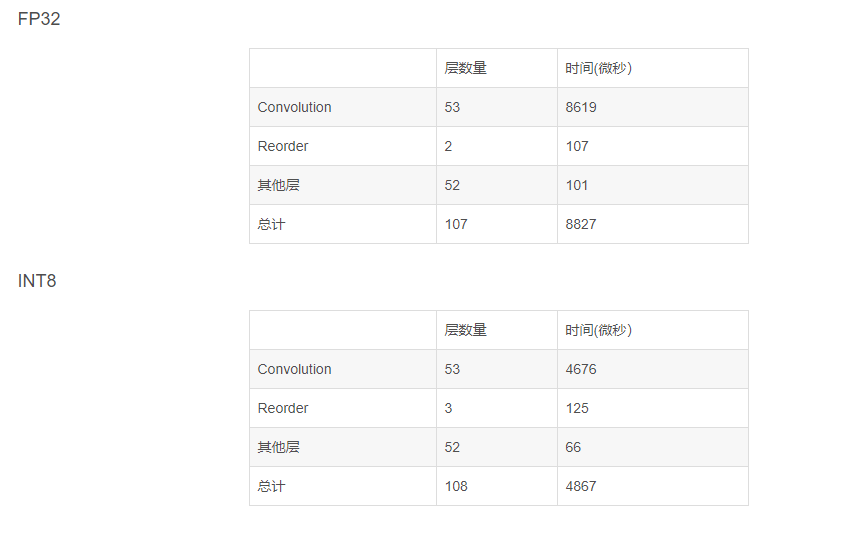
Can be seen that basically is the start of the reasoning through a Reorder start INT8 convolution, and then he INT8 convolution computation, until the last calculation Softmax before switching back FP32 data, calculate the convolution layer basic save more than half of the time, and an additional layer of the Reorder only adds additional 20 us less than the cost,
MobilenetV2 is a very good INT8 model based on OpenVINO example of improving performance