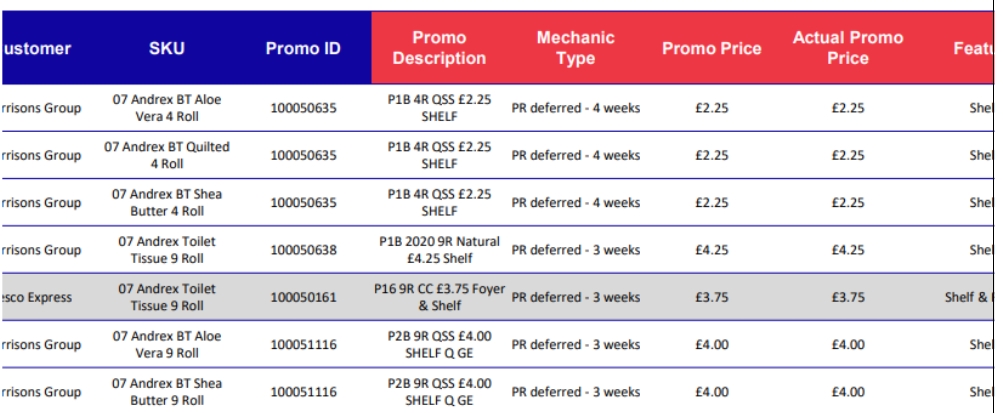
I need to create a new column called 'Feature' using promodescription column
Feature- this has to be extracted from promodescription attribute and the value will be from below
1 week foyer,2 week shelf
1 week foyer, 3 weeks shelf
1 week Golden T,2 weeks shelf
2 weeks Golden T,1 week shelf
Bulk stack
Bulk stack 1
Bulk stack 1
Event space
FOS
Foyer
GE7 151 stores
Gondala End
Ladder rack
Plinth
Shelf
Foyer & shelf
Shelf & foyer
Stack
NA if none of the above are found
For example
| Promodescription | Feature |
|---|---|
| P18 4R QSS $2.25 Shelf | Shelf |
| P18 4R QSS $3.25 foyer and shelf | Foyer and shelf |
So I need to extract the data from promodescription and make a new column called feature so how to do this I have some 1000s is rows please help me with this
CodePudding user response:
This one can produce the exact output you want:
select INITCAP(TRIM(REGEXP_SUBSTR( Promodescription, '[^\$\.0-9]*$' ))) Feature from
values ( 'P18 4R QSS $2.25 Shelf'),
('P18 4R QSS $3.25 foyer and shelf') tmp(Promodescription );
| FEATURE |
|---|
| Shelf |
| Foyer And Shelf |
CodePudding user response:
If the number of characters remains the same (P18 4R QSS $2.25 ), you can try SUBSTR.
create or replace table addcompcolumn (a varchar);
insert into addcompcolumn values ('P18 4R QSS $2.25 Shelf'),('P18 4R QSS $3.25 foyer and shelf');
alter table addcompcolumn ADD column feature varchar as (select substr(a, 17, 16) from addcompcolumn);
select * from addcompcolumn;
Feature
Shelf
Foyer and shelf
https://docs.snowflake.com/en/sql-reference/sql/alter-table-column.html#alter-table-alter-column
You could also try this programmatically or with other string functions
CodePudding user response:
So if we create the "known tokens table"
create or replace table key_words as
select * from values
('1 week foyer,2 week shelf'),
('1 week foyer, 3 weeks shelf'),
('1 week Golden T,2 weeks shelf'),
('2 weeks Golden T,1 week shelf'),
('Bulk stack'),
('Bulk stack 1'),
('Bulk stack 1'),
('Event space'),
('FOS'),
('Foyer'),
('GE7 151 stores'),
('Gondala End'),
('Ladder rack'),
('Plinth'),
('Shelf'),
('Foyer & shelf'),
('Shelf & foyer'),
('Stack')
t(feature);
and then create a "test data" table to do some examples on:
create table main_data as
select * from values
(100050635, 'P1B 4R QSS $2.25 SHELF'),
(100050638, 'P1B 2020 9R Natural $4.25 Shelf'),
(100050161, 'P16 9R CC $3.75 Foyer & Shelf')
t(promo_id, promodescription);
A simple starting solution would be to notice "Shelf" is in two difference cases and to use case insensitive ILIKE
select m.promo_id,
m.promodescription,
f.feature
from main_data as m
left join key_words as f
on m.promodescription ilike '%'||f.feature;
which for my given example data gives:
| PROMO_ID | PROMODESCRIPTION | FEATURE |
|---|---|---|
| 100050635 | P1B 4R QSS $2.25 SHELF | Shelf |
| 100050638 | P1B 2020 9R Natural $4.25 Shelf | Shelf |
| 100050161 | P16 9R CC $3.75 Foyer & Shelf | Shelf |
| 100050161 | P16 9R CC $3.75 Foyer & Shelf | Foyer & shelf |
that last row matches two features. So we can keep only the longest match with a QUALIFY clause and using ROW_NUMBER to rank the row and select the single longest match:
select m.promo_id,
m.promodescription,
f.feature
from main_data as m
left join key_words as f
on m.promodescription ilike '%'||f.feature
qualify row_number() over (partition by m.promo_id order by length(f.feature) desc) = 1;
PROMO_ID |PROMODESCRIPTION |FEATURE 100050161 |P16 9R CC $3.75 Foyer & Shelf |Foyer & shelf 100050635 |P1B 4R QSS $2.25 SHELF |Shelf 100050638 |P1B 2020 9R Natural $4.25 Shelf |Shelf
Then we have to deal with the NA part..
new data:
create or replace table main_data as
select * from values
(100050635, 'P1B 4R QSS $2.25 SHELF'),
(100050638, 'P1B 2020 9R Natural $4.25 Shelf'),
(100050161, 'P16 9R CC $3.75 Foyer & Shelf'),
(1, 'THIS MATCHES NOTHING')
t(promo_id, promodescription);
Now we can use NVL to give us a value when the left join did not match.
select m.promo_id,
m.promodescription,
nvl(f.feature,'NA') as feature
from main_data as m
left join key_words as f
on m.promodescription ilike '%'||f.feature
qualify row_number() over (partition by m.promo_id order by length(f.feature) desc) = 1;
gives:
| PROMO_ID | PROMODESCRIPTION | FEATURE |
|---|---|---|
| 1 | THIS MATCHES NOTHING | NA |
| 100050161 | P16 9R CC $3.75 Foyer & Shelf | Foyer & shelf |
| 100050635 | P1B 4R QSS $2.25 SHELF | Shelf |
| 100050638 | P1B 2020 9R Natural $4.25 Shelf | Shelf |