I am following a 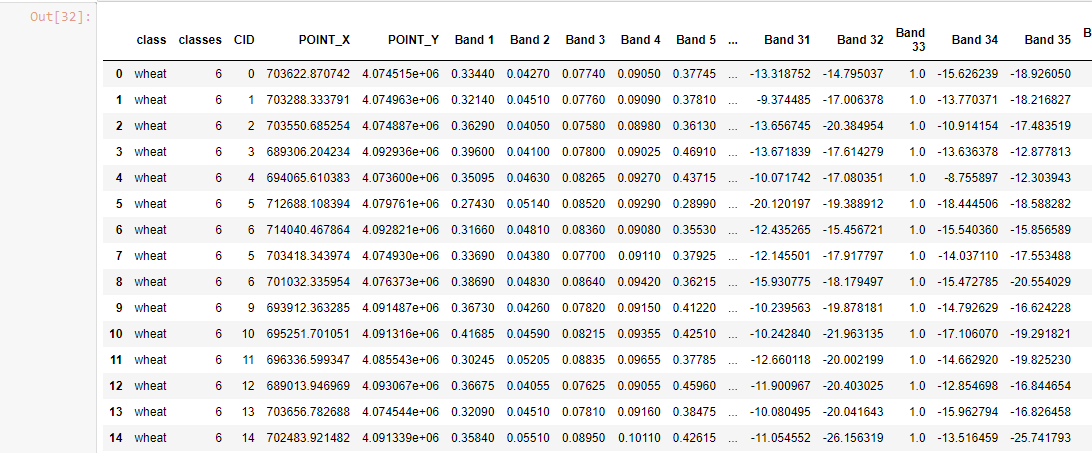 And then I run this code to get the sub-plots with this code:
And then I run this code to get the sub-plots with this code:
prof = train_pts.groupby (['classes']).mean ()
fig = plt.figure(figsize = (17,20))
band_n = [ 'B2', 'B3', 'B4', 'B8' ,'NDVI' ,'VH', 'VV']
n = 1
for ba in band_n:
ax = fig.add_subplot(4,2,n)
ax.title.set_text(ba)
band_val = prof[prof.columns[prof.columns.to_series().str.contains(ba)]]
for index, row in band_val.iterrows():
color = cmap (index)
ax.plot (row,color=color)
ax.autoscale(enable=True, axis="both", tight=None)
ax.set_xticklabels([str (x) for x in range(1, len(row) 1)])
ax.legend(loc='best', fontsize='small', ncol=2, labels=class_names)
n=n 1
The out is this: 
But instead this is the output that I wanted to get : 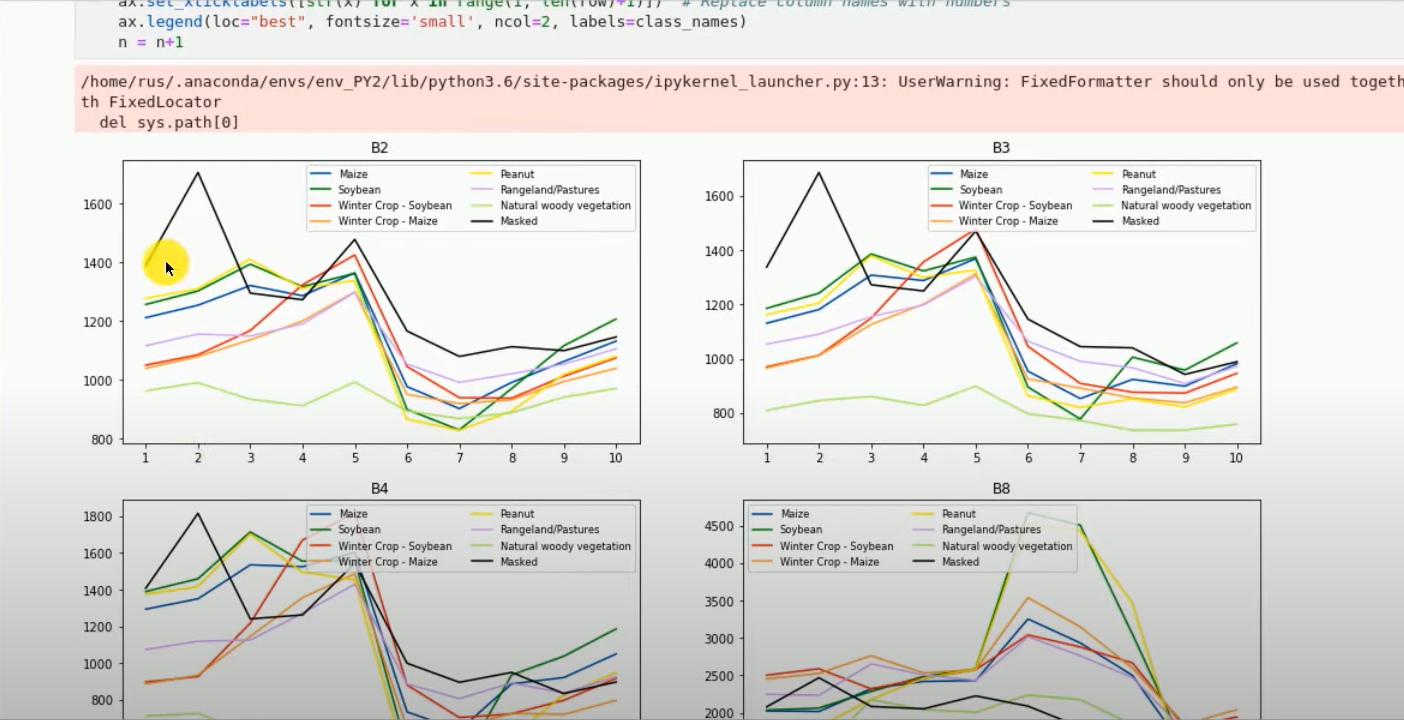
I also double-check the projections of the raster and the point data, it's same. What else I can do?
CodePudding user response:
matplotlib.pyplot.plot creates line plots. When you loop through both rows and columns as you're doing, you end up with only a single point passed to each plot command, so you're plotting a bunch of lines with length 0.
I think you want matplotlib.pyplot.scatter, and to pass the full columns of x, y, and c as arguments. From the plt.scatter docs:
matplotlib.pyplot.scatter(x, y, s=None, c=None, marker=None, cmap=None, norm=None, vmin=None, vmax=None, alpha=None, linewidths=None, *, edgecolors=None, plotnonfinite=False, data=None, **kwargs)
A scatter plot of y vs. x with varying marker size and/or color.Parameters
x, y : float or array-like, shape (n, )
The data positions....
c : array-like or list of colors or color, optional
The marker colors.
So, to plot all points in the raster, just plot once per column:
for i, ba in enumerate(band_n):
ax = fig.add_subplot(4, 2, i 1)
band_val = prof[prof.columns[prof.columns.str.contains(ba)]]
# check to make sure you're matching exactly one column
assert band_val.shape[1] == 1, (
f"unexpected columns: {band_val.columns}"
)
ax.scatter(
x=prof['POINT_X'],
y=prof['POINT_Y'],
c=band_val.iloc[:, 0],
)
Depending on the size of your data and the point density, this may take a long time to render, and the points themselves may overlap. Instead, you may want to check out matplotlib.pyplot.pcolormesh, which can plot data on a regular grid.
That said, if your data is on a regular grid, you may want to check out xarray, which is set up well for working with gridded data. You'd need to make sure that your x and y values are indices of a regular, complete grid, e.g. every value of y is exactly repeated for every combination of x. But if that's the case, you could convert your dataframe to an xarray dataset with df.to_xarray: ds = prof.set_index(['POINT_X', 'POINT_Y']).to_xarray() then plot with ds[band_name].plot().