I would like to rank a column called Number after grouping by the column ID but the ranking would be done only if Variable_1 is True. If Variable_1 is False, assign directly to the new column Rank the highest rank : 1
data={'ID':["A","A","B","C","D","D"], 'Variable_1':[True,True,False,False,True,True], 'Number': [10,20,5,6,100,90]}
df=pd.DataFrame(data)
I tried to do the following but did not work:
df["Rank"] = np.where(df.Variable_1, df.groupby(["ID"])[["Number"]].rank(method='dense', ascending=False), 1)
This is the expected output:
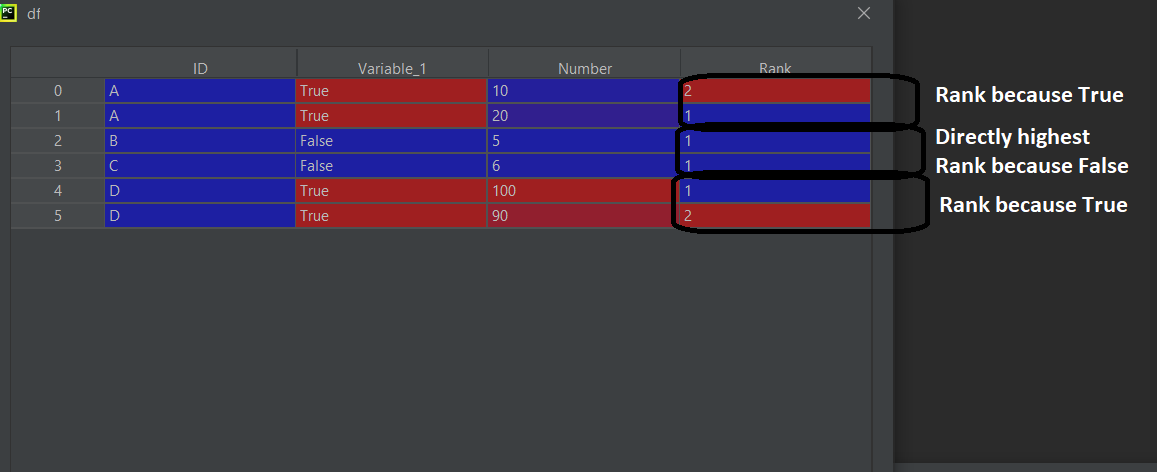
CodePudding user response:
You can first set column Rank to 1 and use pandas.groupby and compute rank. At the end write rank for those rows that have Variable_1 == True with pandas.mask.
df['Rank'] = 1
res = df.groupby('ID')['Number'].rank(ascending=False)
df['Rank'] = df['Rank'].mask(df['Variable_1'], res)
print(df)
ID Variable_1 Number Rank
0 A True 10 2
1 A True 20 1
2 B False 5 1
3 C False 6 1
4 D True 100 1
5 D True 90 2