Lets say I have the following data frame:
df <- data.frame(id = c(1,1,1,2,2,2,3,3,3,3),
col1 = c("a","a", "b", "c", "d", "e", "f", "g", "h", "g"),
start_day = c(NA,1,15, NA, 4, 22, 5, 11, 14, 18),
end_day = c(NA,2, 15, NA, 6, 22, 6, 12, 16, 21))
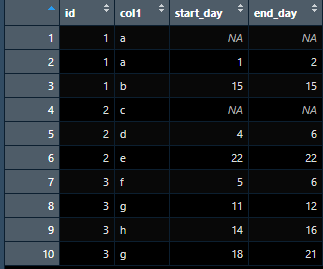
I want to create a data frame that has the following columns: id, start_day, end_day
such that for each unique id I only need the minimum of start_day column and the maximum of the end_day column. The final data frame should look like as follow:
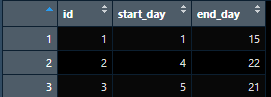
To get this new data frame I wrote the following code:
df <- df[!(is.na(df$start_day)), ]
dt <- data.frame(matrix(ncol =3 , nrow = length(unique(df$id))))
colnames(dt) <- c("id", "start_day", "end_day")
dt$id <- unique(df$id)
st_day <- vector()
en_day <- vector()
for (elm in dt$id) {
d <- df[df$id == elm, ]
minimum <- min(d$start_day)
maximum <- max(d$end_day)
st_day <- c(st_day, minimum)
en_day <- c(en_day, maximum)
}
dt$start_day <- st_day
dt$end_day <- en_day
df <- dt
My code is creating what I am looking for, but I am not happy with it. I would love to learn a better and cleaner way to do the same thing. Any idea is very much appreciated.
CodePudding user response:
You can try data.table like below
> library(data.table)
> na.omit(setDT(df))[, .(start_day = min(start_day), end_day = max(end_day)), id]
id start_day end_day
1: 1 1 15
2: 2 4 22
3: 3 5 21
CodePudding user response:
This should do:
df %>% group_by(id) %>% summarise(start_day = min(start_day, na.rm = T),
end_day = max(end_day, na.rm = T))
Output:
id start_day end_day
<dbl> <dbl> <dbl>
1 1 1 15
2 2 4 22
3 3 5 21