I am struggling to reshape my pandas dataframe from wide to long (I know kind of a ridiculously easy task - sorry for that - but I am completely stuck right now).
Problem is, that the categorical affiliation is not unambiguously given by a variable but by the relative position within the dataframe. Meaning the description of one row defines the subcategory of all following rows of higher hierarchy, until a variable of the same hierarchy as the one defining the subcategory starts the next one, etc.
Guess it's easiest described with an example:
import pandas as pd
df = pd.DataFrame(data = {'Category': ['Fruits', 'Apple', 'Green', 'Red', 'Pineapple', 'Banana', 'Vegetables', 'Potatoes', 'Salad', 'Meat'],
'Value': [10, 5, 2, 3, 3, 2, 4, 2, 2, 3],
'Hierarchy': [1, 2, 3, 3, 2, 2, 1, 2, 2, 1]})
df
Out[87]:
Category Value Hierarchy
0 Fruits 10 1
1 Apple 5 2
2 Green 2 3
3 Red 3 3
4 Pineapple 3 2
5 Banana 2 2
6 Vegetables 4 1
7 Potatoes 2 2
8 Salad 2 2
9 Meat 3 1
What I want should look something like this:
Value Hierarchy1 Hierarchy2 Hierarchy3
1 2 Fruits Apple Green
2 3 Fruits Apple Red
3 3 Fruits Fruits Pineapple
4 2 Fruits Fruits Banana
5 2 Vegetables Vegetables Potatoes
6 2 Vegetables Vegetables Salad
7 3 Meat Meat Meat
Importantly, it should work for an infinite amount of hierarchy-levels.
As I see it, df.wide_to_long() does not have this functionality built in and the only custom solution I could come up with (which is not even working yet) were loops with if statements.
Any idea of a better approach than that or even some built in functionality I did oversee?
CodePudding user response:
In case someone comes along and has a similar problem, this is my custom solution for it:
import pandas as pd
df = pd.DataFrame(data = {'Category': ['Fruits', 'Apple', 'Green', 'Red', 'Pineapple', 'Banana', 'Vegetables', 'Potatoes', 'Soft', 'Hard', 'Salade', 'Meat'],
'Value': [10, 5, 2, 3, 3, 2, 4, 2, 1, 1, 2, 3],
'Hierarchy': [1, 1, 2, 3, 2, 2, 1, 2, 3, 3, 3, 1]})
def c_sunburst(df):
# Find different hierarchy levels
levels = [x for x in df['Hierarchy'].unique()]
# Reshape df to reflect hierarchies in wide format
df_wide = pd.DataFrame(data = {'Hierarchy ' str(level): [] for level in levels})
df_wide['Value'] = []
for i in range(len(df) - 1): # i is index run variable
if not df['Hierarchy'][i] < df['Hierarchy'][i 1]: # Excludes all rows that are not most granular level
ind = i
hierarchies = []
while(df['Hierarchy'][ind] > 1):
hierarchies = [df[list(df)[0]][max([x for x in list(range(0, ind)) if df['Hierarchy'][x] < df['Hierarchy'][i]])]] hierarchies
ind = max([x for x in list(range(0, ind)) if df['Hierarchy'][x] < df['Hierarchy'][i]])
hierarchies = hierarchies [df[list(df)[0]][i]]
rows = pd.DataFrame(data = {'Hierarchy ' str(level): [hi] for level, hi in zip(levels, hierarchies)})
rows['Value'] = df['Value'][i]
df_wide = pd.concat([df_wide, rows], ignore_index = True)
# Add last df row, which is always most granular level
ind = len(df) - 1
i = ind
hierarchies = []
while(df['Hierarchy'][ind] > 1):
hierarchies = [df[list(df)[0]][max([x for x in list(range(0, ind)) if df['Hierarchy'][x] < df['Hierarchy'][i]])]] hierarchies
ind = max([x for x in list(range(0, ind)) if df['Hierarchy'][x] < df['Hierarchy'][i]])
hierarchies = hierarchies [df[list(df)[0]][i]]
rows = pd.DataFrame(data = {'Hierarchy ' str(level): [hi] for level, hi in zip(levels, hierarchies)})
rows['Value'] = df['Value'][i]
df_wide = pd.concat([df_wide, rows], ignore_index = True)
return(df_wide)
This adds NaN instead of carrying less granularly defined categories all the way through but changing this is obv a minor task which I leave to you.
CodePudding user response:
Sunburst could be drawn by parent-child and value, just like Graph Theory, we only concern the relationship between nodes.
import pandas as pd
import numpy as np
import plotly.express as px
df = pd.DataFrame(data = {'Category': ['Fruits', 'Apple', 'Green', 'Red', 'Pineapple', 'Banana', 'Vegetables', 'Potatoes', 'Salad', 'Meat'],
'Value': [10, 5, 2, 3, 3, 2, 4, 2, 2, 3],
'Hierarchy': [1, 2, 3, 3, 2, 2, 1, 2, 2, 1]})
print(df)
###
Category Value Hierarchy
0 Fruits 10 1
1 Apple 5 2
2 Green 2 3
3 Red 3 3
4 Pineapple 3 2
5 Banana 2 2
6 Vegetables 4 1
7 Potatoes 2 2
8 Salad 2 2
9 Meat 3 1
We can use matrix cross manipulation to find the parent of each Category
v = df['Hierarchy'].values[:, None]
print(v)
###
[[1]
[2]
[3]
[3]
[2]
[2]
[1]
[2]
[2]
[1]]
h = df['Hierarchy'].values
print(h)
###
[1 2 3 3 2 2 1 2 2 1]
m = h - v > 0
m[np.tril_indices(m.shape[1])] = False
print(m)
###
[[False True True True True True False True True False]
[False False True True False False False False False False]
[False False False False False False False False False False]
[False False False False False False False False False False]
[False False False False False False False False False False]
[False False False False False False False False False False]
[False False False False False False False True True False]
[False False False False False False False False False False]
[False False False False False False False False False False]
[False False False False False False False False False False]]
In every column's last True indicates the parent's index
occ = np.argwhere(m == True)
df['parent'] = pd.DataFrame(occ).groupby(1).last()
print(df)
###
Category Value Hierarchy parent
0 Fruits 10 1 NaN
1 Apple 5 2 0.0
2 Green 2 3 1.0
3 Red 3 3 1.0
4 Pineapple 3 2 0.0
5 Banana 2 2 0.0
6 Vegetables 4 1 NaN
7 Potatoes 2 2 6.0
8 Salad 2 2 6.0
9 Meat 3 1 NaN
Find their corresponding parents
df['parent'] = df['parent'].map(df['Category'].to_dict())
print(df)
###
Category Value Hierarchy parent
0 Fruits 10 1 NaN
1 Apple 5 2 Fruits
2 Green 2 3 Apple
3 Red 3 3 Apple
4 Pineapple 3 2 Fruits
5 Banana 2 2 Fruits
6 Vegetables 4 1 NaN
7 Potatoes 2 2 Vegetables
8 Salad 2 2 Vegetables
9 Meat 3 1 NaN
Plot
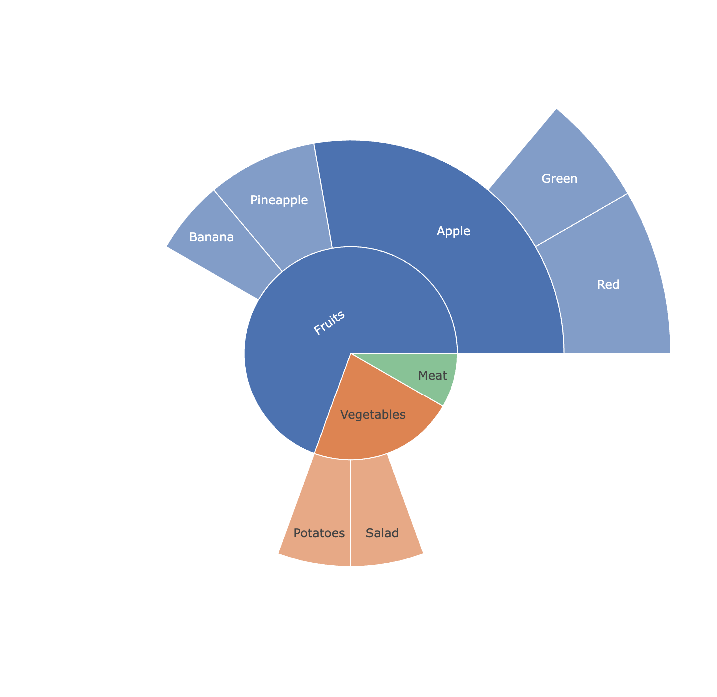
fig = px.sunburst(
df,
names='Category',
parents='parent',
values='Value',
color='Value',
template='simple_white',
width=800,
height=800
)
fig.show()
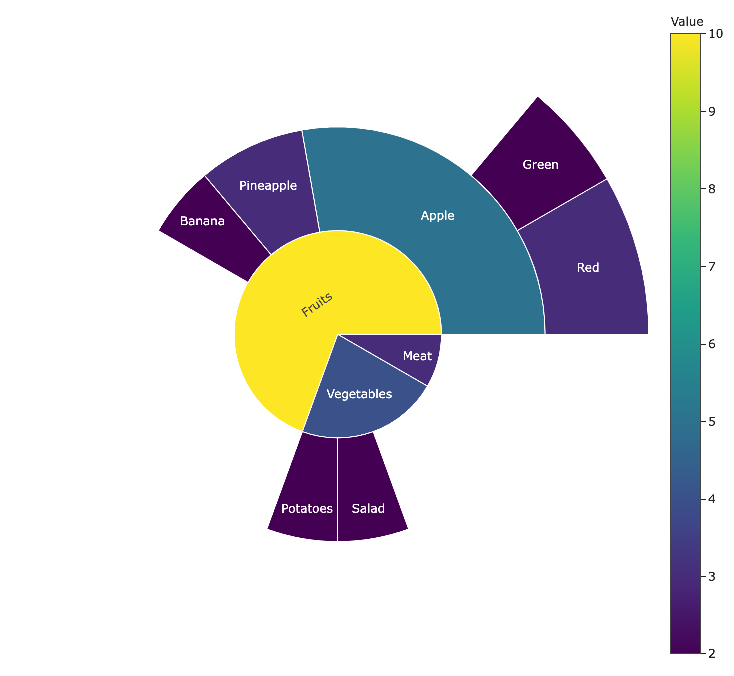
Color without value
fig = px.sunburst(
df,
names='Category',
parents='parent',
values='Value',
# color='Value',
template='seaborn',
width=800,
height=800
)
fig.show()