Recently, I learned how to write a loop that initializes some number, and then randomly generates numbers until the initial number is guessed (while recording the number of guesses it took) such that no number will be guessed twice:
# https://stackoverflow.com/questions/73216517/making-sure-a-number-isnt-guessed-twice
all_games <- vector("list", 100)
for (i in 1:100){
guess_i = 0
correct_i = sample(1:100, 1)
guess_sets <- 1:100 ## initialize a set
trial_index <- 1
while(guess_i != correct_i){
guess_i = sample(guess_sets, 1) ## sample from this set
guess_sets <- setdiff(guess_sets, guess_i) ## remove it from the set
trial_index <- trial_index 1
}
## no need to store `i` and `guess_i` (as same as `correct_i`), right?
game_results_i <- data.frame(i, trial_index, guess_i, correct_i)
all_games[[i]] <- game_results_i
}
all_games <- do.call("rbind", all_games)
I am now trying to modify the above code to create the following two loops:
(Deterministic) Loop 1 will always guess the midpoint (round up) and told if their guess is smaller or bigger than the correct number. They will then re-take the midpoint (e.g. their guess and the floor/ceiling) until they reach the correct number.
(Semi-Deterministic) Loop 2 first makes a random guess and is told if their guess is bigger or smaller than the number. They then divide the difference by half and makes their next guess randomly in a smaller range. They repeat this process many times until they reach the correct number.
I tried to write a sketch of the code:
#Loop 2:
correct = sample(1:100, 1)
guess_1 = sample(1:100, 1)
guess_2 = ifelse(guess_1 > correct, sample(50:guess_1, 1), sample(guess_1:100, 1))
guess_3 = ifelse(guess_2 > correct, sample(50:guess_2, 1), sample(guess_2:100, 1))
guess_4 = ifelse(guess_4 > correct, sample(50:guess_3, 1), sample(guess_3:100, 1))
#etc
But I am not sure if I am doing this correctly.
- Can someone please help me with this?
Thank you!
Example : Suppose I pick the number 68
Loop 1: first random guess = 51, (100-51)/2 51 = 75, (75-50)/2 50 = 63, (75 - 63)/2 63 = 69, (69 - 63)/2 63 = 66, etc.
Loop 2: first random guess = 53, rand_between(53,100) = 71, rand_between(51,71) = 65, rand(65,71) = 70, etc.
CodePudding user response:
I don't think you need a for loop for this, you can create structures since the beginning, with sample, sapply and which:
## correct values can repeat, so we set replace to TRUE
corrects <- sample(1:100, 100, replace = TRUE)
## replace is by default FALSE in sample(), if you don't want repeated guesses
## sapply() creates a matrix
guesses <- sapply(1:100, function(x) sample(1:100, 100))
## constructing game_results_i equal to yours, but could be simplified
game_results_i <- data.frame(
i = 1:100,
trial_index = sapply(
1:100,
function(x) which(
## which() returns the index of the first element that makes the predicate true
guesses[, x] == corrects[x]
)
),
guess_i = corrects,
correct_i = corrects # guess_i and correct_i are obviously equal
)
CodePudding user response:
Ok, let's see if now I match question and answer properly :)
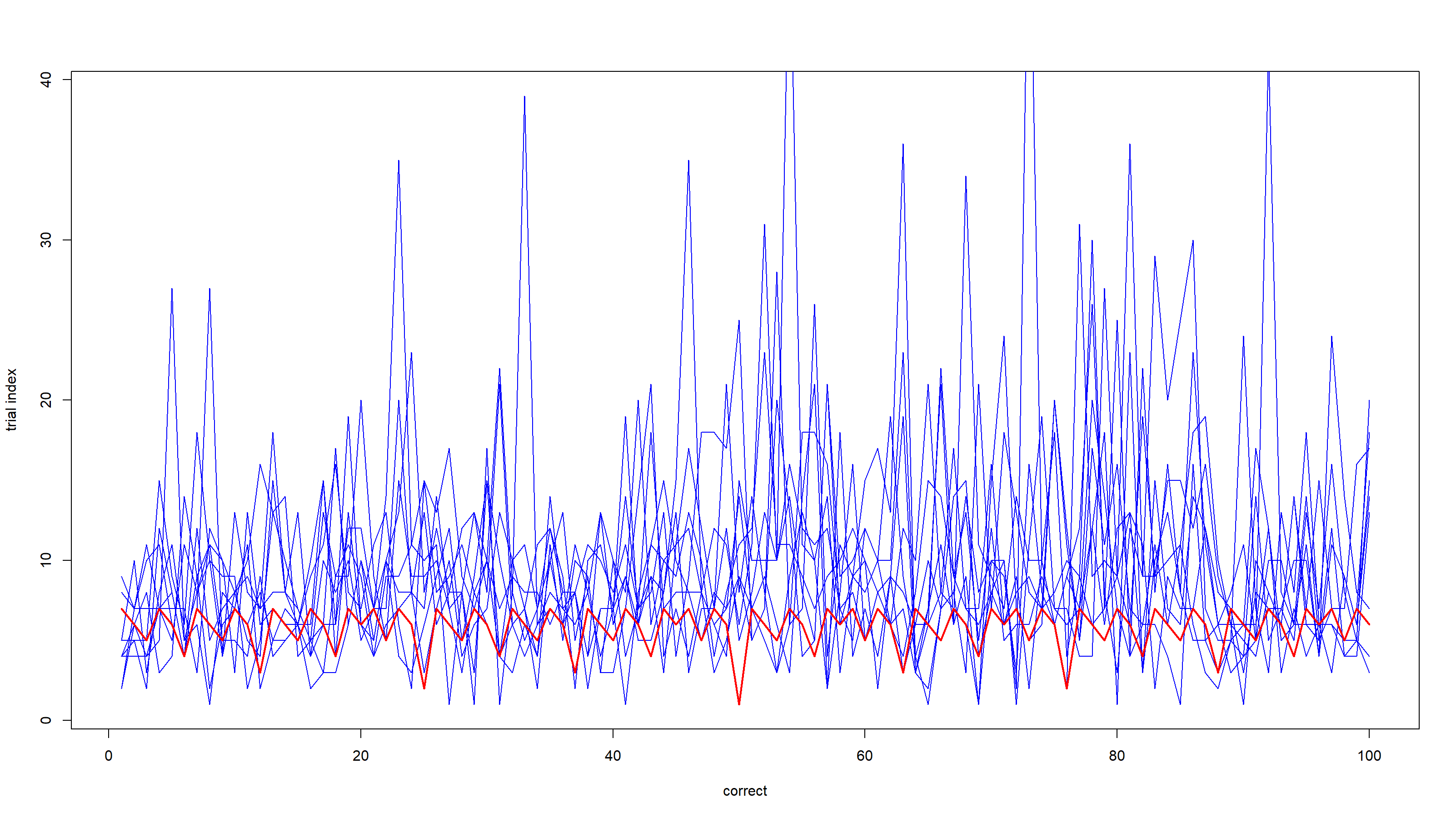
If I got correctly your intentions, in both loops, you are setting increasingly finer lower and upper bounds. Each guess reduces the search space. However, this interpretation does not always match your description, please double check if it can be acceptable for your purposes.
I wrote two functions, guess_bisect for the deterministic loop_1 and guess_sample for loop_2:
guess_bisect <- function(correct, n = 100) {
lb <- 0
ub <- n 1
trial_index <- 1
guess <- round((ub - lb) / 2) lb
while (guess != correct) {
# cat(lb, ub, guess, "\n") # uncomment to print the guess iteration
if (guess < correct)
lb <- guess
else
ub <- guess
guess <- round((ub - lb) / 2) lb
trial_index <- trial_index 1
}
trial_index
}
guess_sample <- function(correct, n = 100) {
lb <- 0
ub <- n 1
trial_index <- 1
guess <- sample((lb 1):(ub - 1), 1)
while (guess != correct) {
# cat(lb, ub, guess, "\n") # uncomment to print the guess iteration
if (guess < correct)
lb <- guess
else
ub <- guess
guess <- sample((lb 1):(ub - 1), 1)
trial_index <- trial_index 1
}
trial_index
}
Obviously, guess_bisect always produces the same results with the same input, guess_sample changes randomly instead.
By plotting the results in a simple chart, it seems that the deterministic bisection is on the average much better, as the random sampling may become happen to pick improvements from the wrong sides. x-axis is the correct number, spanning 1 to 100, y-axis is the trial index, with guess_bisect you get the red curve, with many attempts of guess_sample you get the blue curves.