import requests
import pandas as pd
import csv
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36"
}
urls = [
'https://stats.ncaa.org/game/play_by_play/12465',
'https://stats.ncaa.org/game/play_by_play/12755',
'https://stats.ncaa.org/game/play_by_play/12640',
'https://stats.ncaa.org/game/play_by_play/12290',
]
s = requests.Session()
s.headers.update(headers)
for url in urls:
r = s.get(url)
dfs = pd.read_html(r.text)
for df in dfs:
df.to_csv('pbp.csv', mode='a', index=False)
I have this amazing script I've struggled through (with the help of this community). It pulls the table data from these different sites, and pushes to a CSV.
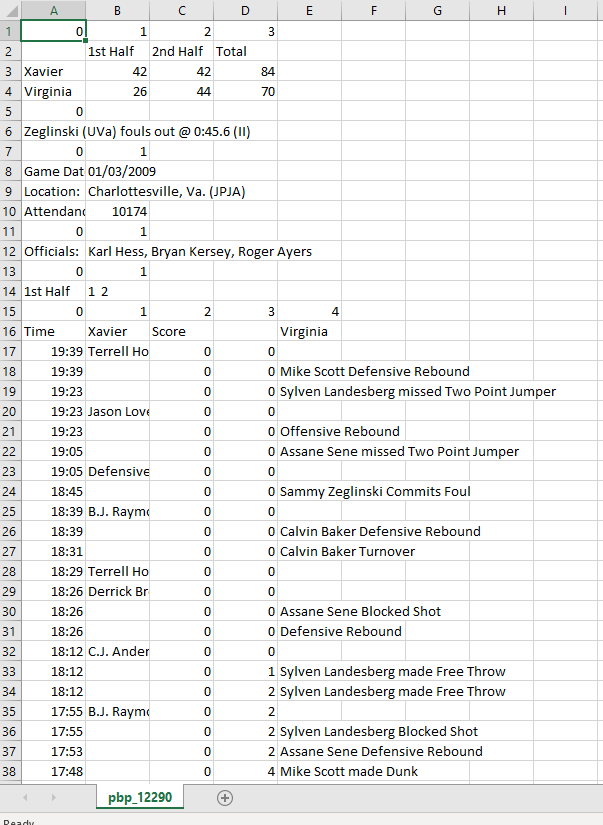
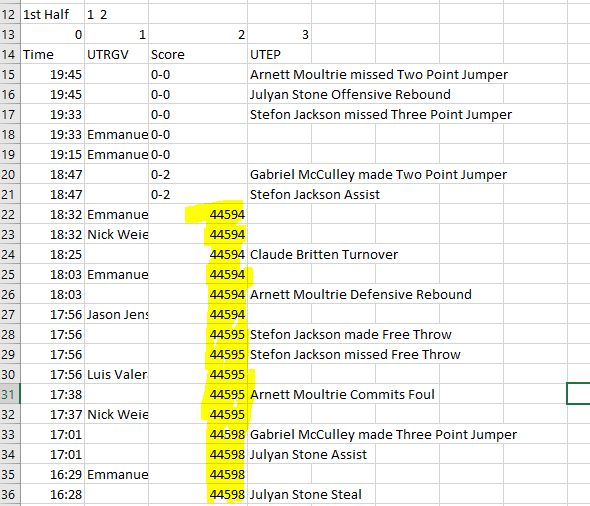
For some reason, the "Score" in some places loses it's format (Image below). I've tried formatting in Excel/Sheets, but no luck.
I don't see anything different in Inspector with these lines -- it's not all of them, only a select few on each link.
Any way I could prevent this from happening? Doesn't make much sense to me.
CodePudding user response:
Seems like it's converting the scores to dates, no? Maybe you can cast that column to string?
dfs = pd.read_html(r.text, converters={'Score': lambda x: str(x)})
I'd try that...
CodePudding user response:
Thinking about it further, you can keep the values a integers and not having it confused as a date object if we just split the column. I also separated each game into separate files as well.
import requests
import pandas as pd
import csv
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36"
}
urls = [
'https://stats.ncaa.org/game/play_by_play/12465',
'https://stats.ncaa.org/game/play_by_play/12755',
'https://stats.ncaa.org/game/play_by_play/12640',
'https://stats.ncaa.org/game/play_by_play/12290',
]
s = requests.Session()
s.headers.update(headers)
for url in urls:
gameId = url.split('/')[-1]
r = s.get(url)
dfs = pd.read_html(r.text)
for df in dfs:
if len(df.columns) > 2:
if df.iloc[0,2] == 'Score':
df[4] = df[3]
df[[2,3]] = df[2].str.split('-', expand=True)
df.to_csv('pbp_%s.csv' %gameId, mode='a', index=False)
Output: