The code works fine and outputs exactly what I need, but when db_diff_3 gets above about 5k lines, it spits out a memory error and breaks. It is using a lot of memory here (almost 7gbs) when running. A 5K list should be small for a list of series which is why I'm not understanding why its doing this. Any help would be appreciated. Sample of db_diff_full_2 below code.
db_diff_3 = []
db_diff_drops = []
db_diff_adds = []
for r, c in db_diff_full_2.iterrows():
for i in db_diff_full_2.columns.get_level_values(0):
if db_diff_full_2.loc[r, (i, 'Old')] != db_diff_full_2.loc[r, (i, 'New')]: #compare old vs new values for each column (i) in each row. if at least one col has a difference, append entire row.
try:
if len(db_diff_full_2.loc[r, ('CompanyName', 'New')]) < 1:
#db_diff_drops.append(db_diff_full_2.loc[r]) # add new add records to separate frame. can shut this line off to aid in memory useage
db_diff_full_2.drop(index=[r], inplace=True) #drop new add records from file
#print('Dropped', r)
break
elif len(db_diff_full_2.loc[r, ('CompanyName', 'Old')]) < 1:
#db_diff_adds.append(db_diff_full_2.loc[r]) # add deleted records to separate frame - these likely were dissolved. can shut this line off to aid in memory useage
db_diff_full_2.drop(index=[r], inplace=True) #drop deleted records from main list
#print('Added', r)
break
else:
db_diff_3.append(db_diff_full_2.loc[r]) # add any records with changes in old vs new columns values to changes file
break
except np.core._exceptions.MemoryError: #exception if export file is too large
print("File too large to export!!")
return #end script if cannot add any more lines to main db_diff_3```
``` CompanyName ... IncorporationDate
Old New ... Old New
CompanyNumber ...
08209948 ! LTD ! LTD ... 11/09/2012 11/09/2012
11399177 !? LTD !? LTD ... 05/06/2018 05/06/2018
11743365 !BIG IMPACT GRAPHICS LIMITED !BIG IMPACT GRAPHICS LIMITED ... 28/12/2018 28/12/2018
13404790 !GOBERUB LTD !GOBERUB LTD ... 17/05/2021 17/05/2021
13522064 !NFOGENIE LTD !NFOGENIE LTD ... 21/07/2021 21/07/2021```
CodePudding user response:
I'm not sure why your code gives a memory error but I wanted to share an approach that doesn't require the for loop and I believe shouldn't cause a memory issue.
The main idea is to separate the old and new parts of your df2 table into separate tables to make comparing easier. I've created an example test table and the variable df2 refers to your db_diff_full_2
import pandas as pd
#Create an example table
df2 = pd.DataFrame({
('Company_name','Old'):['A','B','C','D','E'],
('Company_name','New'):['A','','C','D','E'],
('IncorporationDate','Old'):['Jan 1','Jan 2','Jan 3','Jan 4','Jan 5'],
('IncorporationDate','New'):['Jan 8','Jan 2','Jan 3','Jan 4','Jan 5'],
})
df2.index.name = 'CompanyNumber'
print(df2)
#Separate old and new columns into separate tables
old = df2.loc[:,pd.IndexSlice[:,'Old']]
new = df2.loc[:,pd.IndexSlice[:,'New']]
#Drop the multi-column index on old/new
old.columns = old.columns.droplevel(1)
new.columns = new.columns.droplevel(1)
#Test whether each row has ANY mismatches between old and new in any column
any_column_mismatch = old.ne(new).any(axis=1)
#Test if the old or new name is blank (in which case we don't want it to go to df3)
old_name_not_blank = old['Company_name'].apply(len).gt(0)
new_name_not_blank = new['Company_name'].apply(len).gt(0)
df3 = df2.loc[any_column_mismatch & old_name_not_blank & new_name_not_blank].copy()
print(df3)
Here's what df2 looks like:
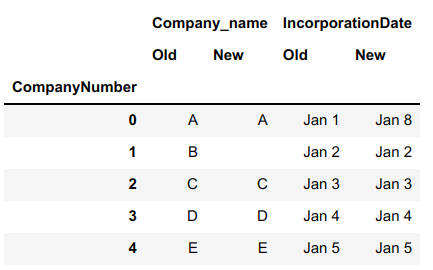
Only the CompanyNumber 0 row is copied to df3. The CompanyNumber 1 is not copied over because the New name is blank
