If I have this df called feature_df:
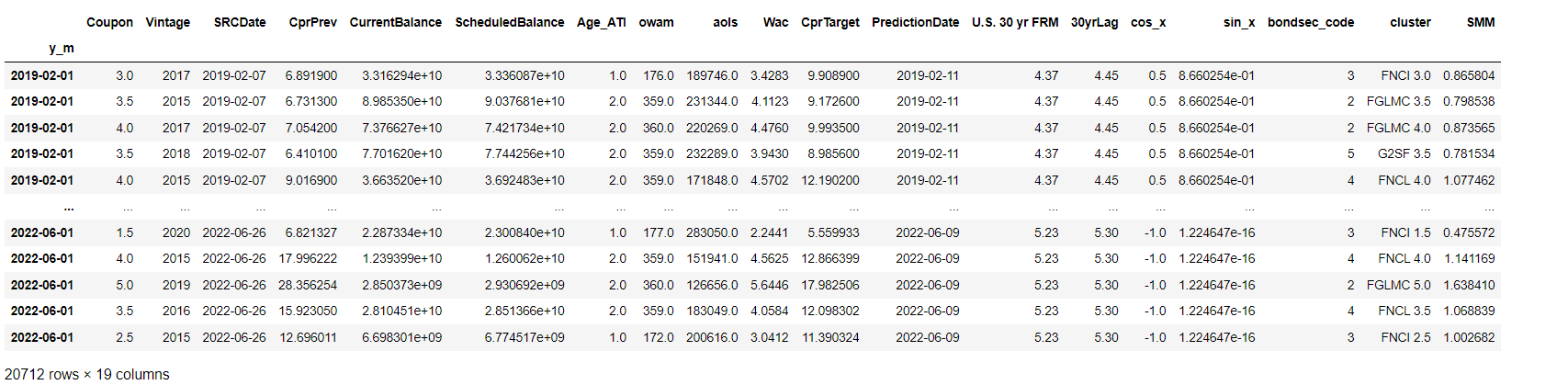
Each row represents a particular "cohort" of mortgage loan groups. I want to select the Wac from each row and create a new column called lagged_WAC which is filled with Wac values from the month prior, based on the datetime index called y_m. Additionally, each lagged Wac must correspond with the Vintage and cluster column values for that row. That is why there are repeats for each date. Each row contains data for each mortgage cohort (Vintage, Coupon, and bondsec_code) at that time. The dataset starts at February 2019 though, so there wouldn't be any "previous months values" for any of those rows. How can I do this?
Here is a more reproducible example with just the index and Wac column:
Wac
y_m
2019-04-01 3.4283
2019-04-01 4.1123
2019-04-01 4.4760
2019-04-01 3.9430
2019-04-01 4.5702
... ...
2022-06-01 2.2441
2022-06-01 4.5625
2022-06-01 5.6446
2022-06-01 4.0584
2022-06-01 3.0412
I have tried implementing this code to generate a copy dataframe and then lagged values by a month, then merging back with the original, but I'm not sure how to check that the Wac_y values returned with the new merged df are correct:
df1 = feature_df.copy().reset_index()
df1['new_date'] = df1['y_m'] pd.DateOffset(months=-1)
df1 = df1[['Wac', 'new_date']]
feature_df.merge(df1, left_index=True, right_on = 'new_date')
For example, there are values for 2019-01-01 which I don't know where they come from since the original dataframe doesn't have data for that month, and the shape goes from 20,712 rows to 12,297,442 rows
CodePudding user response:
I can't test it because I don't have representative data, but from what I see you could try something like this.
df['lagged_WAC'] = df.groupby('cluster', sort=False, as_index=False)['Wac'].shift(1)
If each month has unique clusters for each Wac value, you can groupby cluster and then shift the each row in a group by one to the past. If you need to groupby more than one column you need to pass a list to the groupby like df.groupby(['Vintage', 'cluster']).
Made a little example dataset to show you what I'm thinking of. This is my input:
Month Wac cluster
0 2017-04-01 2.271980 car
1 2017-04-01 2.586608 bus
2 2017-04-01 2.071009 plane
3 2017-04-01 2.102676 boat
4 2017-05-01 2.222338 car
5 2017-05-01 2.617924 bus
6 2017-05-01 2.377280 plane
7 2017-05-01 2.150043 boat
8 2017-06-01 2.203132 car
9 2017-06-01 2.072133 bus
10 2017-06-01 2.223499 plane
11 2017-06-01 2.253821 boat
12 2017-07-01 2.228020 car
13 2017-07-01 2.717485 bus
14 2017-07-01 2.446508 plane
15 2017-07-01 2.607244 boat
16 2017-08-01 2.116647 car
17 2017-08-01 2.820238 bus
18 2017-08-01 2.186937 plane
19 2017-08-01 2.827701 boat
df['lagged_WAC'] = df.groupby('cluster', sort=False,as_index=False)['Wac'].shift(1)
print(df)
Output:
Month Wac cluster lagged_WAC
0 2017-04-01 2.271980 car NaN
1 2017-04-01 2.586608 bus NaN
2 2017-04-01 2.071009 plane NaN
3 2017-04-01 2.102676 boat NaN
4 2017-05-01 2.222338 car 2.271980
5 2017-05-01 2.617924 bus 2.586608
6 2017-05-01 2.377280 plane 2.071009
7 2017-05-01 2.150043 boat 2.102676
8 2017-06-01 2.203132 car 2.222338
9 2017-06-01 2.072133 bus 2.617924
10 2017-06-01 2.223499 plane 2.377280
11 2017-06-01 2.253821 boat 2.150043
12 2017-07-01 2.228020 car 2.203132
13 2017-07-01 2.717485 bus 2.072133
14 2017-07-01 2.446508 plane 2.223499
15 2017-07-01 2.607244 boat 2.253821
16 2017-08-01 2.116647 car 2.228020
17 2017-08-01 2.820238 bus 2.717485
18 2017-08-01 2.186937 plane 2.446508
19 2017-08-01 2.827701 boat 2.607244
the first month has only Nan because there is no earlier month.
Each car in that df has now the value for car in the previous month, each boat for boat in the previous month and so on.