I have a dataframe as given below.My objective is that for each pf_customer_id I would require the top 5 columns (from highest to lowest).I tried using group by and doing transpose however filtering the highest 5 column is a challenge.
{'A': {0: 0.0, 1: 1916.714416, 2: 4022.357547, 3: 6275.28689, 4: 582.863581},
'B': {0: 1916.714416, 1: 0.0, 2: 2105.715414, 3: 4358.78689, 4: 2499.358343},
'C': {0: 4022.357547, 1: 2105.715414, 2: 0.0, 3: 2253.29093, 4: 4604.71567},
'D': {0: 6275.28689, 1: 4358.78689, 2: 2253.29093, 3: 0.0, 4: 6857.928954},
'E': {0: 582.863581, 1: 2499.358343, 2: 4604.71567, 3: 6857.928954, 4: 0.0},
'F': {0: 970.716604,
1: 2887.214892,
2: 4992.857468,
3: 7245.929486,
4: 388.227816},
'G': {0: 1235.716107,
1: 3152.215475,
2: 5257.785928,
3: 7510.859423,
4: 653.301411},
'H': {0: 6508.144182,
1: 4591.6443,
2: 2486.290843,
3: 233.217505,
4: 7090.928801},
'I': {0: 3256.328289,
1: 1340.025712,
2: 766.557835,
3: 3019.314118,
4: 3838.883097},
'J': {0: 2698.412148,
1: 782.275937,
2: 1324.562498,
3: 3577.356653,
4: 3281.013733},
'K': {0: 3147.725445,
1: 1231.310389,
2: 874.905741,
3: 3127.932009,
4: 3730.362069},
'L': {0: 3116.819967,
1: 1200.43964,
2: 905.919746,
3: 3158.947766,
4: 3699.30572},
'M': {0: 1904.334099,
1: 18.283597,
2: 2118.335643,
3: 4371.368639,
4: 2486.953355},
'N': {0: 2353.462836,
1: 436.955498,
2: 1669.340686,
3: 3922.224931,
4: 2935.946158},
'O': {0: 2913.365253,
1: 996.876837,
2: 1109.455848,
3: 3362.429984,
4: 3495.788897},
'P': {0: 2157.443161,
1: 242.20937,
2: 1865.553245,
3: 4118.418641,
4: 2739.958665},
'pf_customer_id': {0: 60000, 1: 60001, 2: 60002, 3: 60003, 4: 60004}}
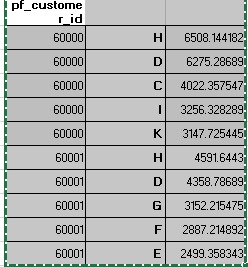
Expected output is shown below. Just taking an instance of two customer ID to make it more easy to understand:
CodePudding user response:
IIUC, you can use:
(df.set_index('pf_customer_id').stack()
.groupby(level=0)
.nlargest(5)
.droplevel(0)
.reset_index(name='value')
)
Output:
pf_customer_id level_1 value
0 60000 H 6508.144182
1 60000 D 6275.286890
2 60000 C 4022.357547
3 60000 I 3256.328289
4 60000 K 3147.725445
5 60001 H 4591.644300
6 60001 D 4358.786890
7 60001 G 3152.215475
8 60001 F 2887.214892
9 60001 E 2499.358343
...
CodePudding user response:
If you are looking to dynamically get the top 5 of a column you can use cumcount()
import pandas as pd
df = pd.DataFrame({
'Column1' : ['A', 'A', 'A', 'A', 'A', 'A', 'B', 'B', 'B', 'B', 'B', 'B'],
'Column2' : [1, 2, 3, 4, 5, 6, 10, 20, 30, 40, 50, 60]
})
df.loc[df.sort_values('Column2', ascending = True).groupby(['Column1'])['Column2'].cumcount() 1 <= 5]
CodePudding user response:
You can simply grab the column values and use an argsort:
df2 = df.set_index('pf_customer_id')
col_names = np.array(list(df2))
for i in df2.index.values:
row = df2.loc[i]
ordered = col_names[np.argsort(row)[::-1]]
top5 = ordered[:5]
print( "cust id %d: top 5=%s" % (i, ", ".join(top5)) )
#cust id 60000: top 5=H, D, C, I, K
#cust id 60001: top 5=H, D, G, F, E
#cust id 60002: top 5=G, F, E, A, H
#cust id 60003: top 5=G, F, E, A, M
#cust id 60004: top 5=H, D, C, I, K
For your specific output, you can instead use the melt method:
df_melt = df2.melt(ignore_index=False).reset_index(drop=False)
# pf_customer_id variable value
#0 60000 A 0.000000
#1 60001 A 1916.714416
#2 60002 A 4022.357547
#3 60003 A 6275.286890
#4 60004 A 582.863581
#.. ... ... ...
#75 60000 P 2157.443161
#76 60001 P 242.209370
#77 60002 P 1865.553245
#78 60003 P 4118.418641
#79 60004 P 2739.958665
and grab the top 5 using sort/nlargest
df_out = []
for i in df_melt.pf_customer_id.unique():
df_id = df_melt.query("pf_customer_id==%d"% i)
df_top5 = df_id.sort_values(by='value', ascending=False).iloc[:5]
df_out.append(df_top5)
print( pandas.concat(df_out).reset_index(drop=True))
# pf_customer_id variable value
#0 60000 H 6508.144182
#1 60000 D 6275.286890
#2 60000 C 4022.357547
#3 60000 I 3256.328289
#4 60000 K 3147.725445
#5 60001 H 4591.644300
#6 60001 D 4358.786890
#7 60001 G 3152.215475
#8 60001 F 2887.214892
#9 60001 E 2499.358343
#10 60002 G 5257.785928
#11 60002 F 4992.857468
#12 60002 E 4604.715670
#13 60002 A 4022.357547
#14 60002 H 2486.290843
#15 60003 G 7510.859423
#16 60003 F 7245.929486
#17 60003 E 6857.928954
#18 60003 A 6275.286890
#19 60003 M 4371.368639
#20 60004 H 7090.928801
#21 60004 D 6857.928954
#22 60004 C 4604.715670
#23 60004 I 3838.883097
#24 60004 K 3730.362069