I have a dataframe that looks like this. 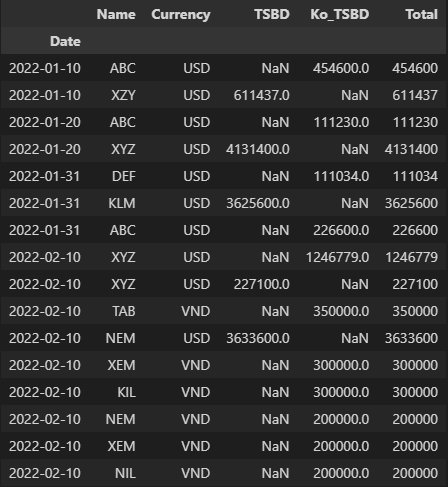
Now i want to create a function to get the sum of the 'Total' column for each of the name 'ABC','XYZ'... with a pre-defined condition of the Currency.
In other words, i want my output to be the same as the following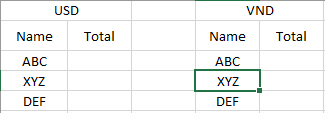
Name_list = list(df['Name'])
Currency_list = list(df['Currency'])
def Calculation(a,b):
for a in Name_list:
for b in Currency_list:
return df['Total'].sum()
result = Calculation('ABC','VND')
print(result)
So far what I have got is just the sum of the whole column 'Total'. Anyone has ideas how to get the desired result for this?
CodePudding user response:
I think pandas' groupby method may help you here:
df.groupby(['Currency', 'Name'])['Total'].sum()
Link to official docs: https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.groupby.html
CodePudding user response:
In your code there is actually nothing that force the function to use only the lines you want to select in your dataframe.
This can be done by using the loc function to locate the lines you want to sum on.
In your example, if you replace le the line return df['Total'].sum() by this one :
return df.loc[(df['Name'] == a) & (df['Currency'] == b), 'Total').sum()
It should return what you want.