I am trying to assign value of 1 in new column "new_col" with condition based in other column and id column.
Here's my dataframe:

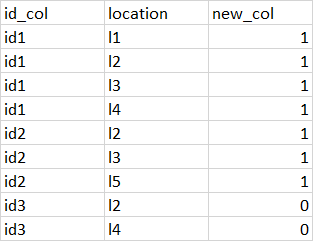
I'd like to add a new column, that would get 1 if "l1" or "l3" is in column "location" for that "id_col".
The expected result:
CodePudding user response:
You could use arrays_overlap after creating an array with 'l1' and 'l3' and collecting all the 'location' values using collect_set as a window function.
Input:
from pyspark.sql import functions as F, Window as W
df = spark.createDataFrame(
[('id1', 'l1'),
('id1', 'l2'),
('id1', 'l3'),
('id1', 'l4'),
('id2', 'l2'),
('id2', 'l3'),
('id2', 'l5'),
('id3', 'l2'),
('id3', 'l4')],
['id_col', 'location'])
Script:
vals = F.array(*map(F.lit, ['l1', 'l3']))
w = W.partitionBy('id_col')
df = df.withColumn(
'new_col',
F.arrays_overlap(vals, F.collect_set('location').over(w)).cast('long')
)
df.show()
# ------ -------- -------
# |id_col|location|new_col|
# ------ -------- -------
# | id1| l1| 1|
# | id1| l2| 1|
# | id1| l3| 1|
# | id1| l4| 1|
# | id2| l2| 1|
# | id2| l3| 1|
# | id2| l5| 1|
# | id3| l2| 0|
# | id3| l4| 0|
# ------ -------- -------
Another way would be using exists:
w = W.partitionBy('id_col')
df = df.withColumn(
'new_col',
F.exists(F.collect_set('location').over(w), lambda x: x.isin('l1', 'l3')).cast('long')
)