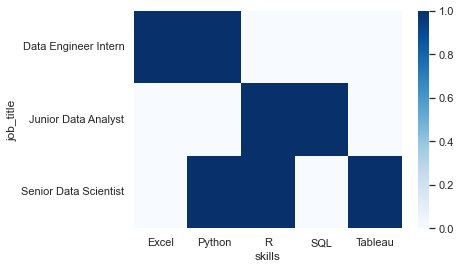
I have a df that looks like this:
df = pd.DataFrame({
'job_title':['Senior Data Scientist', 'Junior Data Analyst', 'Data Engineer Intern', 'Data Engieneer/Architect', 'Data Analyst/Visualisation'],
'location':['Berlin', 'Frankfurt', 'Munich','Frankfurt', 'Munich'],
'job_desc':['something something Python, R, Tableau something', 'something R and SQL',
'something Power Bi, Excel and Python','something Power Bi, Excel and Python somthing', 'Power BI and R something']})
My objective is to now plot the necessary skills that appear in the job description in job_desc column depending on the job title in job_title. Whats important is that the job titles in 'job_title' need to somehow filtered according to the three roles I mention below.
My idea was to do the following:
- create sub data frames according to the job title for
Data Scientist,Data AnalystandData Engineer - creating new dfs from the ones I created that count the skills in the
job_desc - plot the skills in a bar plot with three sub bar plot according to the role
To do this I have done the following:
1.)
# creating sub datasets according to the three roles above to look further into the different skillset
# data analyst dataset
dfa = df[df['job_title'].str.contains('Data Ana')]
# data scientist dataset
dfs = df[df['job_title'].str.contains('Data Sci')]
# data engineer dataset
dfe = df[df['job_title'].str.contains('Data Eng')]
2.) Here I created a loop and stored the obtained information in a nested dictionary. At first I tried to directly store the data from the loop in new data frames, but I read