I have a data frame that contains a long list of entries.
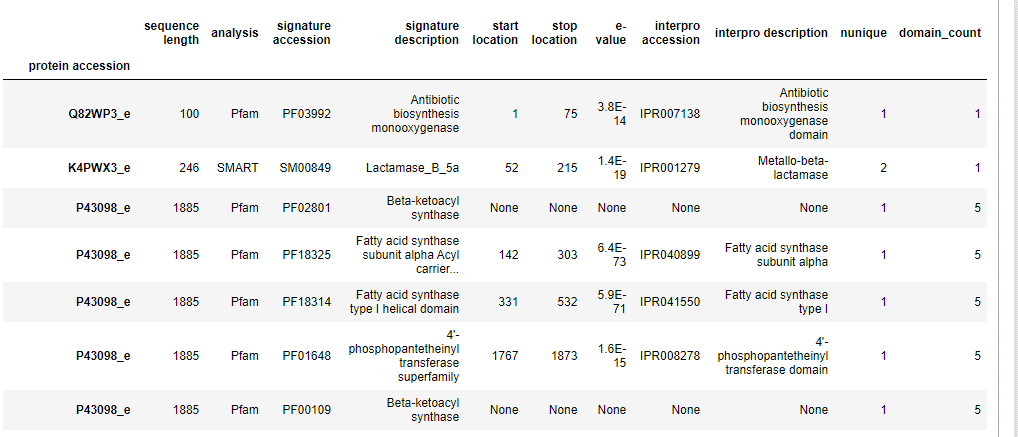
I've indexed them by protein accession numbers. The problem is, they are repeating because some of the proteins consist of multiple domains. I want to make the protein accession numbers the main entries (and it'd have information about how many domains it has - domain_count) and the domains of those proteins to be subentries. For example when I type:
df_filtered.loc['P43098_e', 'domain_count']
it returns the number 5 for each domain (5 times). I want it to print 5 only once since P43098_e would be the main entry to which information about domain_count is directly assigned. Could someone help me, please?
CodePudding user response:
Is that what you're looking for?
if you share the data as a code, I'll be able to hare the result too
df_filtered.loc[df_filtered['protein_accession'] == 'P43098_e', 'domain_count'][:1].values[0]
(df_filtered.loc[df_filtered['protein_accession'] == 'P43098_e', 'domain_count']
.head(1)
.squeeze())
OR
(df_filtered[df_filtered['protein_accession'] == 'P43098_e']['domain_count']
.head(1)
.squeeze())
OR
Either you need to reset_index() on df_fitered and run above solutions OR add reset_filtered within the statement, like
(df_filtered.reset_index()[df_filtered.reset_index()['protein_accession'] == 'P43098_e']['domain_count']
.head(1)
.squeeze())