I am trying to create a word cloud in in python. My goal is to have the words in the csv file appear as they are, without the removal of any punctuations. i have tried several approaches, but I am not sure how to do this. Currently, the code I am using removes the punctuations. How can I create the wordcloud without removing the punctuations.
The data that I have is a one-column data in csv format like this (header is CONTENT3).
CONTENT3
NumVeh:SV
Driver_age:25-44
Rd_desc:straightflat
Weather:clear
NumVeh:SV
Weather:clear
The code I used is as follows:
import pandas as pd
import matplotlib.pyplot as plt
from wordcloud import WordCloud, STOPWORDS
comment_words = ''
stopwords = set(STOPWORDS)
# iterate through the csv file
for val in df1.CONTENT3:
# typecaste each val to string
val = str(val)
# split the value
tokens = val
tokens = val.split()
# Converts each token into lowercase
for i in range(len(tokens)):
tokens[i] = tokens[i].lower()
comment_words = " ".join(tokens) " "
wordcloud = WordCloud(width = 2000, height = 2000,
random_state=1, background_color='white', colormap='Set2', collocations=True,
stopwords = stopwords,
min_font_size = 10).generate(comment_words)
# plot the WordCloud image
plt.figure(figsize = (8, 8), facecolor = None)
plt.imshow(wordcloud)
plt.axis("off")
plt.tight_layout(pad = 0)
plt.show()
The result is below. Although the underscores appear, the colons and other punctuations are automatically removed.
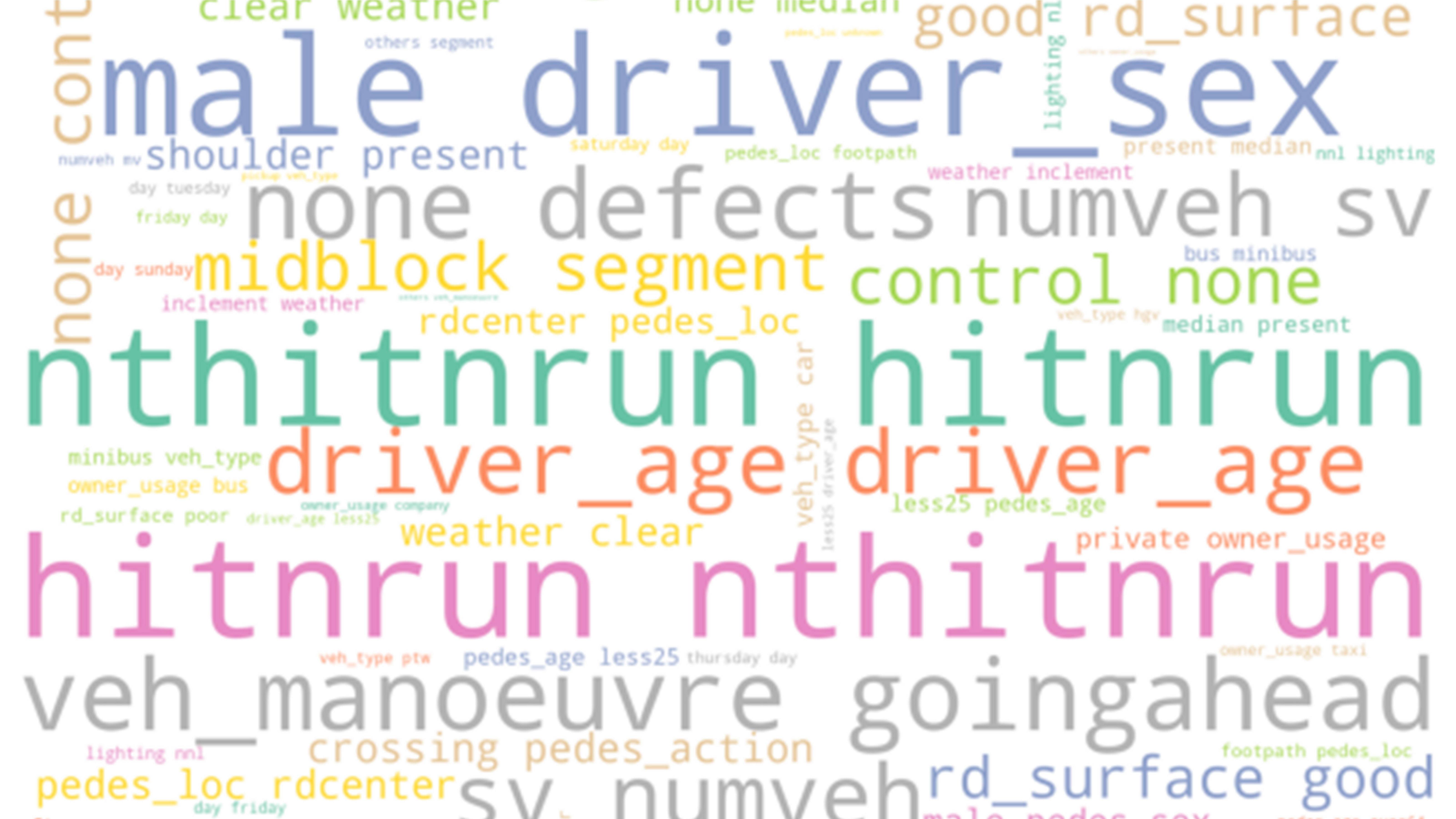
CodePudding user response:
import re
import pandas as pd
import matplotlib.pyplot as plt
from wordcloud import WordCloud, STOPWORDS
comment_words = ''
stopwords = set(STOPWORDS)
# iterate through the csv file
for val in df1.CONTENT3:
# typecaste each val to string
val = str(val)
# split the value on any non-word character
tokens = re.split(r'[^\w] ', val)
# Converts each token into lowercase
for i in range(len(tokens)):
tokens[i] = tokens[i].lower()
comment_words = " ".join(tokens) " "
wordcloud = WordCloud(width = 2000, height = 2000,
random_state=1, background_color='white', colormap='Set2', collocations=False,
stopwords = stopwords,
min_font_size = 10).generate(comment_words)
# plot the WordCloud image
plt.figure(figsize = (8, 8), facecolor = None)
plt.imshow(wordcloud)
plt.axis("off")
plt.tight_layout(pad = 0)
plt.show()
Instead of splitting the value on whitespace, you can split it on a regular expression that matches any non-word character (e.g., [^\w] ). This will allow you to keep the punctuation characters.
You can also pass the collocations argument as False to the WordCloud constructor. This will prevent the word cloud from combining words together, which could potentially remove punctuation characters.
CodePudding user response:
I found a way to deal with this. I created a dictionary using the words and their frequencies. Then, I plotted the wordcloud using the 'generate_from_frequencies' approach. The wordcloud was created with the punctuations as needed.