I have this data frame;(df)
date Name Name_id x1 x2 x3 x4 x5 x6
01/01/2000 00:00 A U_12 1 1 1 1 1 1
01/01/2000 01:00 A U_12
01/01/2000 02:00
01/01/2000 03:00
....
I am trying to calculate the monthly aggregated mean etc. for some columns using lubridate.
what I did so far;
df$date <- dmy_hm(Sites_tot$date)
df$month <- floor_date(df$date,"month")
monthly_avgerage <- df %>%
group_by(Name, Name_id, month) %>%
summarize_at(vars(x1:x4), .funs = c("mean", "min", "max"), na.rm = TRUE)
I can see the values seem okay although some of the months are turned into NAs.
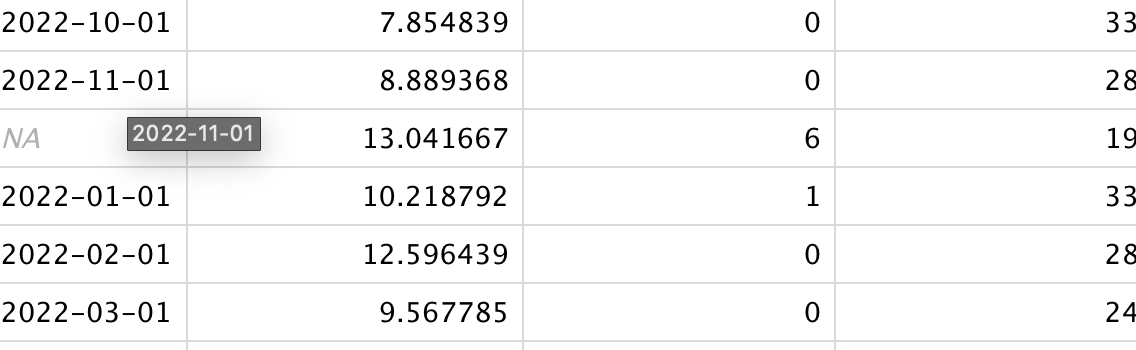
CodePudding user response:
We can modify the summarise_at to
library(dplyr)
df %>%
group_by(Name, Name_id, month) %>%
summarise(across(x1:x4, list(mean = ~ mean(.x, na.rm = TRUE),
min = ~ min(.x, na.rm = TRUE),
max = ~ max(.x, na.rm = TRUE))))
A reproducible example
iris %>%
group_by(Species) %>%
summarise(across(everything(), list(mean = ~ mean(.x, na.rm = TRUE),
min = ~ min(.x, na.rm = TRUE),
max = ~ max(.x, na.rm = TRUE))))
CodePudding user response:
If I am not wrong, the challenge is to get date column into datetime format:
Somehow date = dmy_hm(date) does not work:
library(dplyr)
library(lubridate)
df %>%
mutate(date = dmy_hms(paste0(date, ":00")),
month = month(date)) %>%
group_by(Name, Name_id, month) %>%
summarise(across(x1:x4, list(mean = ~ mean(.x, na.rm = TRUE),
min = ~ min(.x, na.rm = TRUE),
max = ~ max(.x, na.rm = TRUE))), .groups = "drop")
Name Name_id month x1_mean x1_min x1_max x2_mean x2_min x2_max x3_mean x3_min x3_max
<chr> <chr> <dbl> <dbl> <int> <int> <dbl> <int> <int> <dbl> <int> <int>
1 A U_12 1 1.5 1 2 1.5 1 2 1.5 1 2
2 B U_13 1 3.5 3 4 3.5 3 4 3.5 3 4
# … with 3 more variables: x4_mean <dbl>, x4_min <int>, x4_max <int>
# ℹ Use `colnames()` to see all variable names
fake data:
df <- structure(list(date = c("01/01/2000 00:00", "01/01/2000 01:00",
"01/01/2000 02:00", "01/01/2000 03:00"), Name = c("A", "A", "B",
"B"), Name_id = c("U_12", "U_12", "U_13", "U_13"), x1 = 1:4,
x2 = 1:4, x3 = 1:4, x4 = 1:4, x5 = 1:4, x6 = 1:4), class = "data.frame", row.names = c(NA,
-4L))