Hi I am writing a DATABRICKS Python code which picks huge JSON file and divide into two part. Which means from index 0 or "reporting_entity_name" till index 3 or "version" on one file and from index 4 in other file till the end. Though it successfully divides the file from index 1 of the json file but when i provide index 0 it fails and says
Datasource does not support writing empty or nested empty schemas. Please make sure the data schema has at least one or more column(s).
Here is the SAMPLE Data of large JSON file.
{
"reporting_entity_name": "launcher",
"reporting_entity_type": "launcher",
"last_updated_on": "2020-08-27",
"version": "1.0.0",
"in_network": [
{
"negotiation_arrangement": "ffs",
"name": "Boosters",
"billing_code_type": "CPT",
"billing_code_type_version": "2020",
"billing_code": "27447",
"description": "Boosters On Demand",
"negotiated_rates": [
{
"provider_groups": [
{
"npi": [
0
],
"tin": {
"type": "ein",
"value": "11-1111111"
}
}
],
"negotiated_prices": [
{
"negotiated_type": "negotiated",
"negotiated_rate": 123.45,
"expiration_date": "2022-01-01",
"billing_class": "organizational"
}
]
}
]
}
]
}
Here is the python code.
from pyspark.sql.functions import explode, col
import itertools
# Read the JSON file from Databricks storage
df_json = spark.read.option("multiline","true").json("/mnt/BigData_JSONFiles/SampleDatafilefrombigfile.json")
spark.conf.set("spark.sql.execution.arrow.pyspark.enabled", "false")
# Convert the dataframe to a dictionary
data = df_json.toPandas().to_dict()
# Split the data into two parts
d1 = dict(itertools.islice(data.items(), 1))
d2 = dict(itertools.islice(data.items(), 1, len(data.items())))
# Convert the first part of the data back to a dataframe
df1 = spark.createDataFrame([d1])
# Write the first part of the data to a JSON file in Databricks storage
df1.write.format("json").save("/mnt/BigData_JSONFiles/SampleDatafilefrombigfile_detail.json")
# Convert the second part of the data back to a dataframe
df2 = spark.createDataFrame([d2])
# Write the second part of the data to a JSON file in Databricks storage
df2.write.format("json").save("/mnt/BigData_JSONFiles/SampleDatafilefrombigfile_header.json")
Here is the output of the two files. In the output file you can see in the detail file it should only contains the data of "in_network" but it also have the 0 index data which is "reporting_entity_name" which shouldnt be in detail file it should be in header file.
{
"in_network": [
{
"negotiation_arrangement": "ffs",
"name": "Boosters",
"billing_code_type": "CPT",
"billing_code_type_version": "2020",
"billing_code": "27447",
"description": "Boosters On Demand",
"negotiated_rates": [
{
"provider_groups": [
{
"npi": [
0
],
"tin": {
"type": "ein",
"value": "11-1111111"
}
}
],
"negotiated_prices": [
{
"negotiated_type": "negotiated",
"negotiated_rate": 123.45,
"expiration_date": "2022-01-01",
"billing_class": "organizational"
}
]
}
]
}
]
},"negotiation_arrangement":"ffs"}]}}
The output of the Headerfile which starts from 1 index and gives the output.
{"reporting_entity_type": "launcher",
"last_updated_on": "2020-08-27",
"version": "1.0.0"}
Kindly please help me in this error.
A guidance on code will be helpful.
CodePudding user response:
I have reproduced your code and got below results for one file.
{"last_updated_on":{"0":"2020-08-27"},"reporting_entity_name":{"0":"launcher"},"reporting_entity_type":{"0":"launcher"},"version":{"0":"1.0.0"}}

The inner 0 key might be due to the usage of dictionary and pandas.
As your JSON has the same structure, you can try the below workaround to divide the JSON using select rather than converting into dictionary.
This is the Original Dataframe from JSON file.
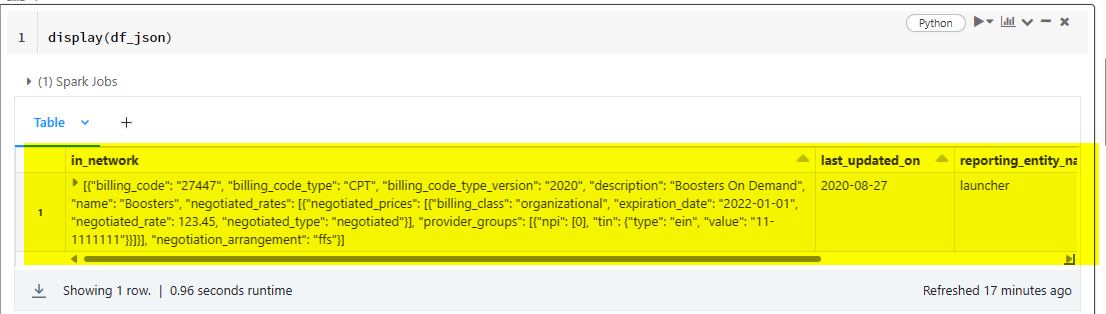
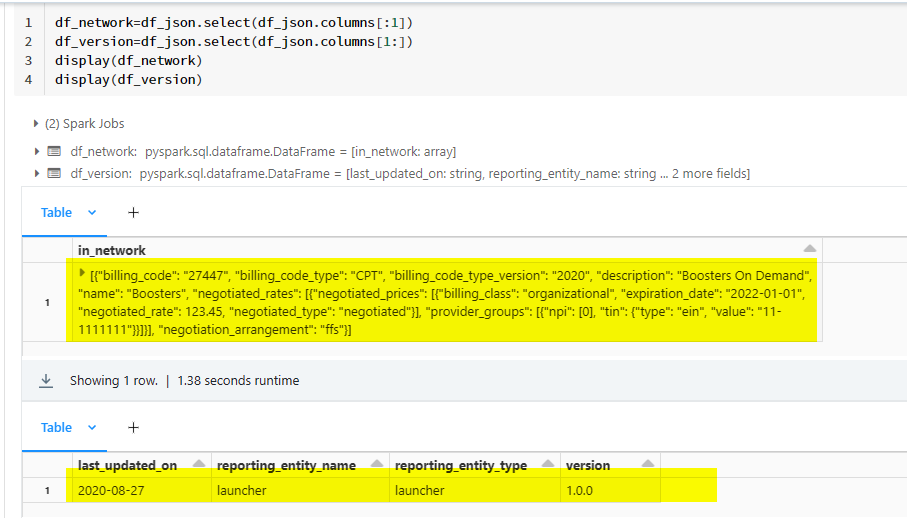
So, use select to generate the required JSON files.
df_network=df_json.select(df_json.columns[:1])
df_version=df_json.select(df_json.columns[1:])
display(df_network)
display(df_version)
Dataframes:
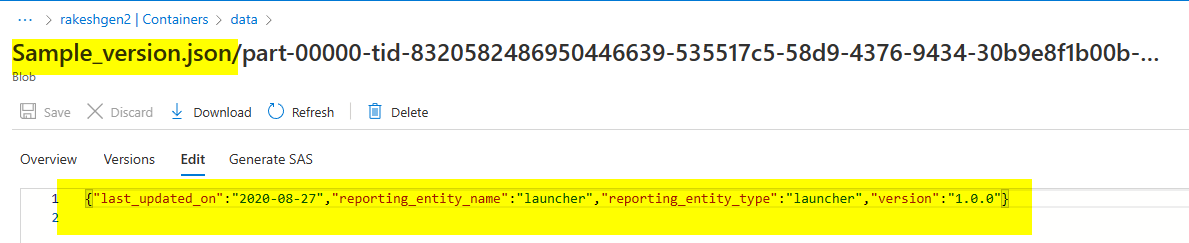
Result after writing to JSON files:

CodePudding user response:
I am getting this error when I use the 2gb JSON file, which is the large form of the JSON file attached above.
Here is the TRACKBACK.
Py4JJavaError Traceback (most recent call last)
<command-1186665458636705> in <cell line: 11>()
9 df_version=df_json.select(df_json.columns[1:])
10
---> 11 df_network.write.format("json").save("/mnt/BigData_JSONFiles/2022-10_040_05C0_in-network-rates_2_of_2_detail.json")
12 df_version.write.format("json").save("/mnt/BigData_JSONFiles/2022-10_040_05C0_in-network-rates_2_of_2_header.json")
13 display(df_network)
/databricks/spark/python/pyspark/instrumentation_utils.py in wrapper(*args, **kwargs)
46 start = time.perf_counter()
47 try:
---> 48 res = func(*args, **kwargs)
49 logger.log_success(
50 module_name, class_name, function_name, time.perf_counter() - start, signature
/databricks/spark/python/pyspark/sql/readwriter.py in save(self, path, format, mode, partitionBy, **options)
966 self._jwrite.save()
967 else:
--> 968 self._jwrite.save(path)
969
970 @since(1.4)
/databricks/spark/python/lib/py4j-0.10.9.5-src.zip/py4j/java_gateway.py in __call__(self, *args)
1319
1320 answer = self.gateway_client.send_command(command)
-> 1321 return_value = get_return_value(
1322 answer, self.gateway_client, self.target_id, self.name)
1323
/databricks/spark/python/pyspark/sql/utils.py in deco(*a, **kw)
194 def deco(*a: Any, **kw: Any) -> Any:
195 try:
--> 196 return f(*a, **kw)
197 except Py4JJavaError as e:
198 converted = convert_exception(e.java_exception)
/databricks/spark/python/lib/py4j-0.10.9.5-src.zip/py4j/protocol.py in get_return_value(answer, gateway_client, target_id, name)
324 value = OUTPUT_CONVERTER[type](answer[2:], gateway_client)
325 if answer[1] == REFERENCE_TYPE:
--> 326 raise Py4JJavaError(
327 "An error occurred while calling {0}{1}{2}.\n".
328 format(target_id, ".", name), value)
Py4JJavaError: An error occurred while calling o672.save.
: org.apache.spark.SparkException: Job aborted.
at org.apache.spark.sql.errors.QueryExecutionErrors$.jobAbortedError(QueryExecutionErrors.scala:882)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$.$anonfun$write$1(FileFormatWriter.scala:334)
at com.databricks.spark.util.FrameProfiler$.record(FrameProfiler.scala:80)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$.write(FileFormatWriter.scala:154)
at org.apache.spark.sql.execution.datasources.InsertIntoHadoopFsRelationCommand.run(InsertIntoHadoopFsRelationCommand.scala:207)
at org.apache.spark.sql.execution.command.DataWritingCommandExec.sideEffectResult$lzycompute(commands.scala:126)
at org.apache.spark.sql.execution.command.DataWritingCommandExec.sideEffectResult(commands.scala:124)
at org.apache.spark.sql.execution.command.DataWritingCommandExec.executeCollect(commands.scala:138)
at org.apache.spark.sql.execution.QueryExecution$$anonfun$$nestedInanonfun$eagerlyExecuteCommands$1$1.$anonfun$applyOrElse$2(QueryExecution.scala:241)
at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withCustomExecutionEnv$8(SQLExecution.scala:243)
at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:392)
at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withCustomExecutionEnv$1(SQLExecution.scala:188)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:985)
at org.apache.spark.sql.execution.SQLExecution$.withCustomExecutionEnv(SQLExecution.scala:142)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:342)
at org.apache.spark.sql.execution.QueryExecution$$anonfun$$nestedInanonfun$eagerlyExecuteCommands$1$1.$anonfun$applyOrElse$1(QueryExecution.scala:241)
at org.apache.spark.sql.execution.QueryExecution.org$apache$spark$sql$execution$QueryExecution$$withMVTagsIfNecessary(QueryExecution.scala:226)
at org.apache.spark.sql.execution.QueryExecution$$anonfun$$nestedInanonfun$eagerlyExecuteCommands$1$1.applyOrElse(QueryExecution.scala:239)
at org.apache.spark.sql.execution.QueryExecution$$anonfun$$nestedInanonfun$eagerlyExecuteCommands$1$1.applyOrElse(QueryExecution.scala:232)
at org.apache.spark.sql.catalyst.trees.TreeNode.$anonfun$transformDownWithPruning$1(TreeNode.scala:512)
at org.apache.spark.sql.catalyst.trees.CurrentOrigin$.withOrigin(TreeNode.scala:99)
at org.apache.spark.sql.catalyst.trees.TreeNode.transformDownWithPruning(TreeNode.scala:512)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.org$apache$spark$sql$catalyst$plans$logical$AnalysisHelper$$super$transformDownWithPruning(LogicalPlan.scala:31)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.transformDownWithPruning(AnalysisHelper.scala:268)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.transformDownWithPruning$(AnalysisHelper.scala:264)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.transformDownWithPruning(LogicalPlan.scala:31)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.transformDownWithPruning(LogicalPlan.scala:31)
at org.apache.spark.sql.catalyst.trees.TreeNode.transformDown(TreeNode.scala:488)
at org.apache.spark.sql.execution.QueryExecution.$anonfun$eagerlyExecuteCommands$1(QueryExecution.scala:232)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$.allowInvokingTransformsInAnalyzer(AnalysisHelper.scala:324)
at org.apache.spark.sql.execution.QueryExecution.eagerlyExecuteCommands(QueryExecution.scala:232)
at org.apache.spark.sql.execution.QueryExecution.commandExecuted$lzycompute(QueryExecution.scala:186)
at org.apache.spark.sql.execution.QueryExecution.commandExecuted(QueryExecution.scala:177)
at org.apache.spark.sql.execution.QueryExecution.assertCommandExecuted(QueryExecution.scala:268)
at org.apache.spark.sql.DataFrameWriter.runCommand(DataFrameWriter.scala:965)
at org.apache.spark.sql.DataFrameWriter.saveToV1Source(DataFrameWriter.scala:430)
at org.apache.spark.sql.DataFrameWriter.saveInternal(DataFrameWriter.scala:397)
at org.apache.spark.sql.DataFrameWriter.save(DataFrameWriter.scala:251)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244)
at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:380)
at py4j.Gateway.invoke(Gateway.java:306)
at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132)
at py4j.commands.CallCommand.execute(CallCommand.java:79)
at py4j.ClientServerConnection.waitForCommands(ClientServerConnection.java:195)
at py4j.ClientServerConnection.run(ClientServerConnection.java:115)
at java.lang.Thread.run(Thread.java:750)
Caused by: org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 14.0 failed 4 times, most recent failure: Lost task 0.3 in stage 14.0 (TID 20) (10.139.92.0 executor 0): org.apache.spark.SparkException: Task failed while writing rows.
at org.apache.spark.sql.errors.QueryExecutionErrors$.taskFailedWhileWritingRowsError(QueryExecutionErrors.scala:886)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$.executeTask(FileFormatWriter.scala:432)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$.$anonfun$write$12(FileFormatWriter.scala:310)
at org.apache.spark.scheduler.ResultTask.$anonfun$runTask$3(ResultTask.scala:75)
at com.databricks.spark.util.ExecutorFrameProfiler$.record(ExecutorFrameProfiler.scala:110)
at org.apache.spark.scheduler.ResultTask.$anonfun$runTask$1(ResultTask.scala:75)
at com.databricks.spark.util.ExecutorFrameProfiler$.record(ExecutorFrameProfiler.scala:110)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:55)
at org.apache.spark.scheduler.Task.doRunTask(Task.scala:169)
at org.apache.spark.scheduler.Task.$anonfun$run$4(Task.scala:137)
at com.databricks.unity.EmptyHandle$.runWithAndClose(UCSHandle.scala:125)
at org.apache.spark.scheduler.Task.$anonfun$run$1(Task.scala:137)
at com.databricks.spark.util.ExecutorFrameProfiler$.record(ExecutorFrameProfiler.scala:110)
at org.apache.spark.scheduler.Task.run(Task.scala:96)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$13(Executor.scala:902)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1696)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$4(Executor.scala:905)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
at com.databricks.spark.util.ExecutorFrameProfiler$.record(ExecutorFrameProfiler.scala:110)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:760)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:750)
Caused by: com.databricks.sql.io.FileReadException: Error while reading file dbfs:/mnt/BigData_JSONFiles/2022-10_040_05C0_in-network-rates_2_of_2.json.
at org.apache.spark.sql.execution.datasources.FileScanRDD$$anon$1$$anon$2.logFileNameAndThrow(FileScanRDD.scala:626)
at org.apache.spark.sql.execution.datasources.FileScanRDD$$anon$1$$anon$2.getNext(FileScanRDD.scala:595)
at org.apache.spark.util.NextIterator.hasNext(NextIterator.scala:73)
at org.apache.spark.sql.execution.datasources.FileScanRDD$$anon$1.nextIterator(FileScanRDD.scala:719)
at org.apache.spark.sql.execution.datasources.FileScanRDD$$anon$1.$anonfun$hasNext$1(FileScanRDD.scala:437)
at scala.runtime.java8.JFunction0$mcZ$sp.apply(JFunction0$mcZ$sp.java:23)
at com.databricks.spark.util.ExecutorFrameProfiler$.record(ExecutorFrameProfiler.scala:110)
at org.apache.spark.sql.execution.datasources.FileScanRDD$$anon$1.hasNext(FileScanRDD.scala:432)
at scala.collection.Iterator$$anon$10.hasNext(Iterator.scala:460)
at org.apache.spark.sql.execution.datasources.FileFormatDataWriter.writeWithIterator(FileFormatDataWriter.scala:90)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$.$anonfun$executeTask$2(FileFormatWriter.scala:412)
at org.apache.spark.util.Utils$.tryWithSafeFinallyAndFailureCallbacks(Utils.scala:1730)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$.executeTask(FileFormatWriter.scala:419)
... 21 more
Caused by: java.lang.IllegalArgumentException: Cannot grow BufferHolder by size 8 because the size after growing exceeds size limitation 2147483632
at org.apache.spark.sql.catalyst.expressions.codegen.BufferHolder.grow(BufferHolder.java:71)
at org.apache.spark.sql.catalyst.expressions.codegen.UnsafeWriter.grow(UnsafeWriter.java:63)
at org.apache.spark.sql.catalyst.expressions.codegen.UnsafeWriter.writeUnalignedBytes(UnsafeWriter.java:127)
at org.apache.spark.sql.catalyst.expressions.codegen.UnsafeWriter.write(UnsafeWriter.java:110)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$SpecificUnsafeProjection.writeFields_0_1$(Unknown Source)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$SpecificUnsafeProjection.writeFields_1_0$(Unknown Source)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$SpecificUnsafeProjection.apply(Unknown Source)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$SpecificUnsafeProjection.apply(Unknown Source)
at scala.collection.Iterator$$anon$10.next(Iterator.scala:461)
at org.apache.spark.sql.execution.datasources.FileScanRDD$$anon$1$$anon$2.getNext(FileScanRDD.scala:557)
... 32 more
Driver stacktrace:
at org.apache.spark.scheduler.DAGScheduler.failJobAndIndependentStages(DAGScheduler.scala:3312)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$abortStage$2(DAGScheduler.scala:3244)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$abortStage$2$adapted(DAGScheduler.scala:3235)
at scala.collection.mutable.ResizableArray.foreach(ResizableArray.scala:62)
at scala.collection.mutable.ResizableArray.foreach$(ResizableArray.scala:55)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:49)
at org.apache.spark.scheduler.DAGScheduler.abortStage(DAGScheduler.scala:3235)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$handleTaskSetFailed$1(DAGScheduler.scala:1424)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$handleTaskSetFailed$1$adapted(DAGScheduler.scala:1424)
at scala.Option.foreach(Option.scala:407)
at org.apache.spark.scheduler.DAGScheduler.handleTaskSetFailed(DAGScheduler.scala:1424)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.doOnReceive(DAGScheduler.scala:3524)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:3462)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:3450)
at org.apache.spark.util.EventLoop$$anon$1.run(EventLoop.scala:51)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$runJob$1(DAGScheduler.scala:1169)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
at com.databricks.spark.util.FrameProfiler$.record(FrameProfiler.scala:80)
at org.apache.spark.scheduler.DAGScheduler.runJob(DAGScheduler.scala:1157)
at org.apache.spark.SparkContext.runJobInternal(SparkContext.scala:2727)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2710)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$.$anonfun$write$1(FileFormatWriter.scala:299)
... 48 more
Caused by: org.apache.spark.SparkException: Task failed while writing rows.
at org.apache.spark.sql.errors.QueryExecutionErrors$.taskFailedWhileWritingRowsError(QueryExecutionErrors.scala:886)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$.executeTask(FileFormatWriter.scala:432)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$.$anonfun$write$12(FileFormatWriter.scala:310)
at org.apache.spark.scheduler.ResultTask.$anonfun$runTask$3(ResultTask.scala:75)
at com.databricks.spark.util.ExecutorFrameProfiler$.record(ExecutorFrameProfiler.scala:110)
at org.apache.spark.scheduler.ResultTask.$anonfun$runTask$1(ResultTask.scala:75)
at com.databricks.spark.util.ExecutorFrameProfiler$.record(ExecutorFrameProfiler.scala:110)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:55)
at org.apache.spark.scheduler.Task.doRunTask(Task.scala:169)
at org.apache.spark.scheduler.Task.$anonfun$run$4(Task.scala:137)
at com.databricks.unity.EmptyHandle$.runWithAndClose(UCSHandle.scala:125)
at org.apache.spark.scheduler.Task.$anonfun$run$1(Task.scala:137)
at com.databricks.spark.util.ExecutorFrameProfiler$.record(ExecutorFrameProfiler.scala:110)
at org.apache.spark.scheduler.Task.run(Task.scala:96)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$13(Executor.scala:902)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1696)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$4(Executor.scala:905)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
at com.databricks.spark.util.ExecutorFrameProfiler$.record(ExecutorFrameProfiler.scala:110)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:760)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
... 1 more
Caused by: com.databricks.sql.io.FileReadException: Error while reading file dbfs:/mnt/BigData_JSONFiles/2022-10_040_05C0_in-network-rates_2_of_2.json.
at org.apache.spark.sql.execution.datasources.FileScanRDD$$anon$1$$anon$2.logFileNameAndThrow(FileScanRDD.scala:626)
at org.apache.spark.sql.execution.datasources.FileScanRDD$$anon$1$$anon$2.getNext(FileScanRDD.scala:595)
at org.apache.spark.util.NextIterator.hasNext(NextIterator.scala:73)
at org.apache.spark.sql.execution.datasources.FileScanRDD$$anon$1.nextIterator(FileScanRDD.scala:719)
at org.apache.spark.sql.execution.datasources.FileScanRDD$$anon$1.$anonfun$hasNext$1(FileScanRDD.scala:437)
at scala.runtime.java8.JFunction0$mcZ$sp.apply(JFunction0$mcZ$sp.java:23)
at com.databricks.spark.util.ExecutorFrameProfiler$.record(ExecutorFrameProfiler.scala:110)
at org.apache.spark.sql.execution.datasources.FileScanRDD$$anon$1.hasNext(FileScanRDD.scala:432)
at scala.collection.Iterator$$anon$10.hasNext(Iterator.scala:460)
at org.apache.spark.sql.execution.datasources.FileFormatDataWriter.writeWithIterator(FileFormatDataWriter.scala:90)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$.$anonfun$executeTask$2(FileFormatWriter.scala:412)
at org.apache.spark.util.Utils$.tryWithSafeFinallyAndFailureCallbacks(Utils.scala:1730)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$.executeTask(FileFormatWriter.scala:419)
... 21 more
Caused by: java.lang.IllegalArgumentException: Cannot grow BufferHolder by size 8 because the size after growing exceeds size limitation 2147483632
at org.apache.spark.sql.catalyst.expressions.codegen.BufferHolder.grow(BufferHolder.java:71)
at org.apache.spark.sql.catalyst.expressions.codegen.UnsafeWriter.grow(UnsafeWriter.java:63)
at org.apache.spark.sql.catalyst.expressions.codegen.UnsafeWriter.writeUnalignedBytes(UnsafeWriter.java:127)
at org.apache.spark.sql.catalyst.expressions.codegen.UnsafeWriter.write(UnsafeWriter.java:110)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$SpecificUnsafeProjection.writeFields_0_1$(Unknown Source)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$SpecificUnsafeProjection.writeFields_1_0$(Unknown Source)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$SpecificUnsafeProjection.apply(Unknown Source)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$SpecificUnsafeProjection.apply(Unknown Source)
at scala.collection.Iterator$$anon$10.next(Iterator.scala:461)
at org.apache.spark.sql.execution.datasources.FileScanRDD$$anon$1$$anon$2.getNext(FileScanRDD.scala:557)
... 32 more
Here is the code where I used above method.
from pyspark.sql.functions import explode, col
import itertools
# Read the JSON file from Databricks storage
df_json = spark.read.option("multiline","true").json("/mnt/BigData_JSONFiles/2022-10_040_05C0_in-network-rates_2_of_2.json")
spark.conf.set("spark.sql.execution.arrow.pyspark.enabled", "false")
df_network=df_json.select(df_json.columns[:1])
df_version=df_json.select(df_json.columns[1:])
df_network.write.format("json").save("/mnt/BigData_JSONFiles/2022-10_040_05C0_in-network-rates_2_of_2_detail.json")
df_version.write.format("json").save("/mnt/BigData_JSONFiles/2022-10_040_05C0_in-network-rates_2_of_2_header.json")
display(df_network)
display(df_version)