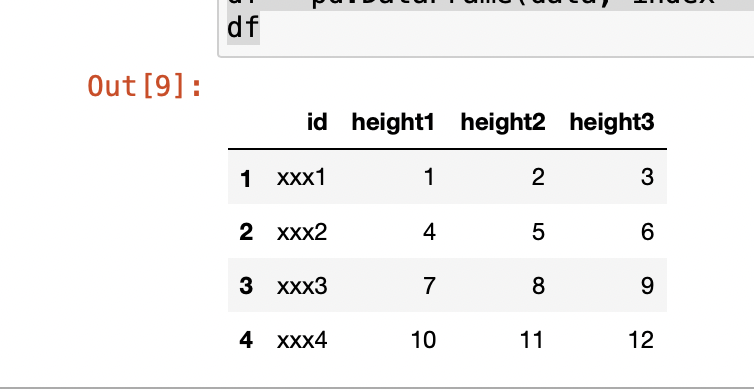
Here I have a table (it is really large, I just give a simplified example)
import pandas as pd
indices = (1,2,3,4)
columns = ["id", "height1", "height2", "height3"]
data = (["xxx1", 1, 2, 3], ["xxx2", 4, 5, 6], ["xxx3", 7, 8, 9], ["xxx4", 10, 11, 12])
df = pd.DataFrame(data, index = indices, columns = columns)
df
which returns
However, what should I do if I want to this dataframe to be displayed in this way? I tried to use groupby(id) and then unstack() but failed.
Any help or hint is welcome
id height score
xxx1 height1 1
xxx1 height2 2
xxx1 height3 3
xxx2 height1 4
xxx2 height2 5
.
.
.
xxx4 height3 12
CodePudding user response:
Let us try just melt
df.melt('id')
id variable value
0 xxx1 height1 1
1 xxx2 height1 4
2 xxx3 height1 7
3 xxx4 height1 10
4 xxx1 height2 2
5 xxx2 height2 5
6 xxx3 height2 8
7 xxx4 height2 11
8 xxx1 height3 3
9 xxx2 height3 6
10 xxx3 height3 9
11 xxx4 height3 12
CodePudding user response:
In [99]: df
Out[99]:
id height1 height2 height3
1 xxx1 1 2 3
2 xxx2 4 5 6
3 xxx3 7 8 9
4 xxx4 10 11 12
In [100]: df.set_index('id').stack().reset_index().set_axis(['id', 'height', 'score'], axis=1)
Out[100]:
id height score
0 xxx1 height1 1
1 xxx1 height2 2
2 xxx1 height3 3
3 xxx2 height1 4
4 xxx2 height2 5
5 xxx2 height3 6
6 xxx3 height1 7
7 xxx3 height2 8
8 xxx3 height3 9
9 xxx4 height1 10
10 xxx4 height2 11
11 xxx4 height3 12
the main stuff is df.set_index('id').stack()
docs: df.stack