The title might not be very accurate, but I have two dataframes that I am adding together. The second dataframe is a copy of the first but I would like the Index and IDs to be continuous, so when the 45th row is reached and the first row of the second dataframe is added on, the first index is 46.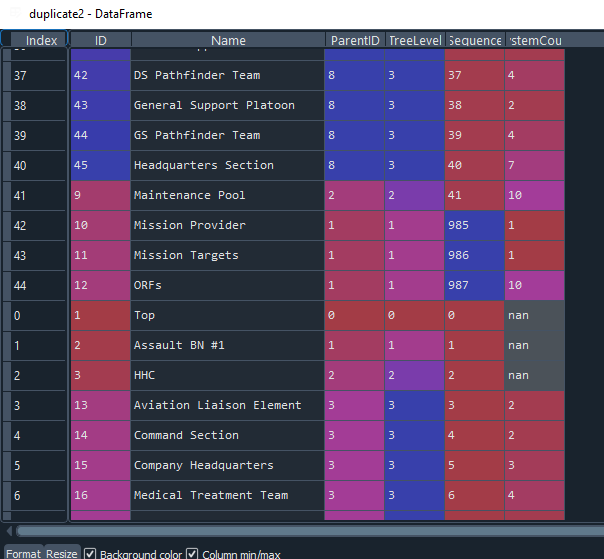
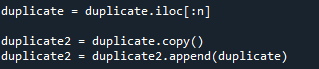
I have been able to find multiple ways to get the indices to be continuous so ignore that part for now. Mostly need the duplicated entries (i.e. the ID column) to start at 46. I believe this would be some sort of renaming panda. Here is an example of the two dataframes.
CodePudding user response:
The following should do the work, assuming that the IDs start counting from 1 in the duplicate['ID']:
duplicate2['ID'] = len(duplicate)
final_df = pd.concat([duplicate, duplicate2], ignore_index=True)