I am currently coding in R and merged two dataframes together so I could include all the information together but I don't want the one column "Cost" to be duplicated multiple times (it was due to the unique values of the last 3 columns). I want it to include the cost 100 only in the first column and then for every other instance where the columns "State", "Market", "Date", and "Cost" are the same as above. I attached what the dataframe looks like and what I want it to be changed to. Thank you!
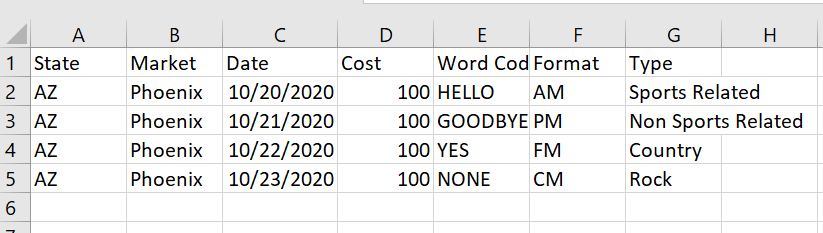
What it currently looks like
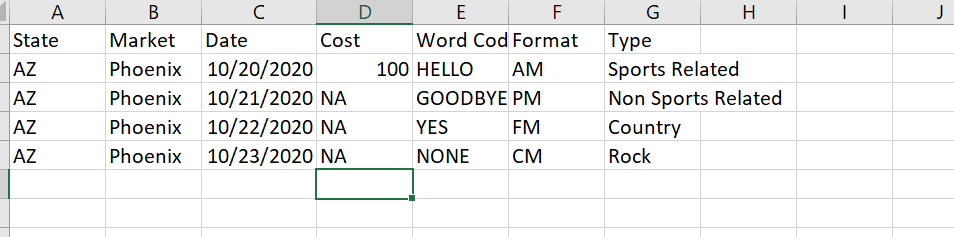
What it should look like
CodePudding user response:
Please use index like in this example:
name_of_your_dataset[nrow_init:nrow_fin, ncol] <- NA
In your case, assuming the name of your dataset as 'data'
data[2:4,4]<- NA
Just leave a positive feedback and if I was useful, just vote this answer up.
CodePudding user response:
Here is a solution using duplicated with your dataframe (df)
State Market Date Cost Word format Type
1 AZ Phoenix 10-20-2020 100 HELLO AM Sports related
2 AZ Phoenix 10-21-2020 NA GOODBYE PM Non Sports related
3 AZ Phoenix 10-22-2020 NA YES FM Country
4 AZ Phoenix 10-23-2020 NA NONE CM Rock
Set duplicates to NA
df$Cost[duplicated(df$Cost)] <- NA
Output:
State Market Date Cost Word format Type
1 AZ Phoenix 10-20-2020 100 HELLO AM Sports related
2 AZ Phoenix 10-21-2020 NA GOODBYE PM Non Sports related
3 AZ Phoenix 10-22-2020 NA YES FM Country
4 AZ Phoenix 10-23-2020 NA NONE CM Rock