I have 2 dataframes df1 and df2 in which df1 contains only 0. Let's call the sets of columns in df1 and df2 by col1 and col2 respectively. For each column name in col2, if it belongs to col1, I will replace the corresponding column in df1 by its counterpart in df2.
In my example, df1 is
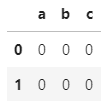
and df2 is
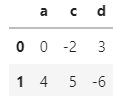
Then my desired result is
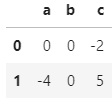
To do so, I use loop through each column name in col2. However, Python returns a warning
PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling
frame.insertmany times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, usenewframe = frame.copy()
Could you elaborate on a more efficient method?
import pandas as pd
import numpy as np
df1 = pd.DataFrame(np.array([[0, 0, 0], [0, 0, 0]]),
columns=['a', 'b', 'c'])
df2 = pd.DataFrame(np.array([[0, -2, 3], [4, 5, -6]]),
columns=['a', 'c', 'd'])
for c in df2.columns:
if c in df1.columns:
df1[c] = df2[c]
CodePudding user response:
You can use DataFrame.update to update existing dataframe. Since, df2 has extra columns that are not in df1 DataFrame.update adds them too. To update only correct columns/index we can use pd.Index.intersection here.
cols = df2.columns.intersection(df1.columns)
idx = df2.index.intersection(df1.index)
df1.update(df2.loc[idx, cols])
print(df1)
a b c
0 0 0 -2
1 4 0 5
CodePudding user response:
I believe by replacing
df1[c] = df2[c]
with
df1[c][:] = df2[c]
you can ensure that you're overwriting the column in-place, rather than inserting a new column with the same name and removing the original one. This should prevent fragmentation. This only works if all your data has the same type though.