I'm trying to pivot my dataframe so that there is a single row and a single cell for each summary X metric comparison. I have tried pivoting this, but can't figure out a sensible index column.
Here is my current output.
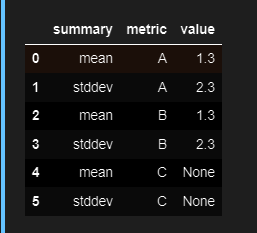
Does anyone know how to achieve my expected output?

To reproduce:
import pandas as pd
pd.DataFrame({'summary': {0: 'mean',
1: 'stddev',
2: 'mean',
3: 'stddev',
4: 'mean',
5: 'stddev'},
'metric': {0: 'A', 1: 'A', 2: 'B', 3: 'B', 4: 'C', 5: 'C'},
'value': {0: '2.0',
1: '1.5811388300841898',
2: '0.4',
3: '0.5477225575051661',
4: None,
5: None}})
CodePudding user response:
Remove missing values by DataFrame.dropna, join columns together, convert to index and transpose by DataFrame.T:
df = df.dropna(subset=['value'])
df['g'] = df['summary'] '_' df['metric']
df = df.set_index('g')[['value']].T.reset_index(drop=True).rename_axis(None, axis=1)
print (df)
mean_A stddev_A mean_B stddev_B
0 2.0 1.5811388300841898 0.4 0.5477225575051661