I'm trying to scrape only one value from this 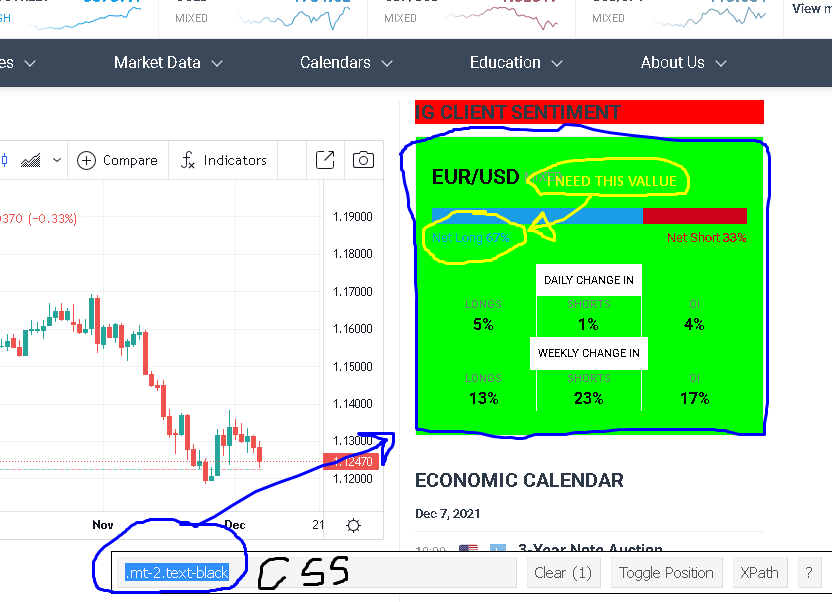
Here is my code
library(RSelenium)
rD <- rsDriver(browser="chrome",port=0999L,verbose = F,chromever = "95.0.4638.54")
remDr <- rD[["client"]]
remDr$navigate("https://www.dailyfx.com/eur-usd")
html <- remDr$getPageSource()[[1]]
library(rvest)
page <- read_html(html)
nodes <- html_nodes(page, css = ".mt-2.text-black")
html_text(nodes)
My result is
html_text(nodes)
[1] "\n\nEUR/USD\nMixed\n\n\n\n\n\n\n\n\n\nNet Long\n\n\n\nNet Short\n\n\n\n\n\nDaily change in\n\n\n\nLongs\n5%\n\n\nShorts\n1%\n\n\nOI\n4%\n\n\n\n\n\nWeekly change in\n\n\n\nLongs\n13%\n\n\nShorts\n23%\n\n\nOI\n17%\n\n\n\n"
What I need to do to get the value of Net Long ?
CodePudding user response:
I would use a more targeted css selector list, to target just the node of interest. Then extract the data-value attribute value from the single matched node to get the percentage:
webElem <- remDr$findElement(using = 'css selector', '.dfx-technicalSentimentCard__netLongContainer [data-type="long-value-info"]')
var <- webElem$getElementAttribute("data-value")[[1]]
Or,
page %>% html_element('.dfx-technicalSentimentCard__netLongContainer [data-type="long-value-info"]') %>% html_attr('data-value')