hi there i am currently working on a little tiny sraper - and i am putting some pieces together
i have an URL which holds record of so called digital hubs: see 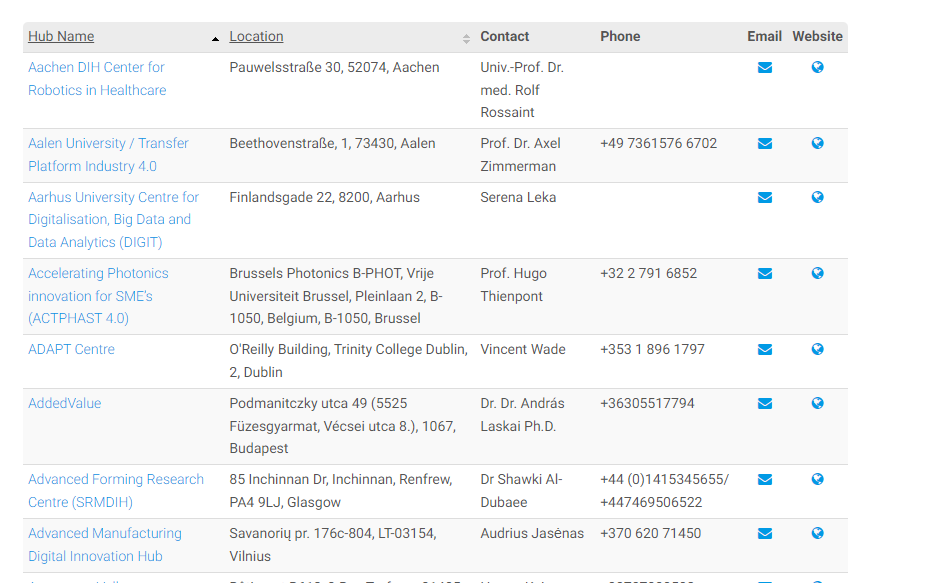

that said - i am just trying to get the data for the other fields of interest - eg. the description text which starts like so:
BaRoN is an initiative bringing together several actors in Bavaria: the TUM Robotics Competence Center founded within the HORSE project, Bavarian Research Alliance (BayFOR), ITZB (Projektträger Bayern)
I applied the ideas of you, Tim to the code. - but it does not work
import requests
from bs4 import BeautifulSoup
from pprint import pprint
url = 'https://s3platform-legacy.jrc.ec.europa.eu/digital-innovation-hubs-tool/-/dih/1096/view'
r = requests.get(url)
soup = BeautifulSoup(r.text, 'html5lib')
# The name of the hub is in the <h4> tag.
hubname = soup.find('h4').text
# All contact info is within a <div class='hubCard'>.
description = soup.find("div", class_="hubCardContent")
cardinfo = {}
# Grab all the <p> tags inside that div. The infoLabel class marks
# the section header.
for data in description.find_all('p'):
if 'infoLabel' in data.attrs.get('class', []):
Description = data.text
cardinfo[Description] = []
else:
cardinfo[Description].append( data.text )
# The contact info is in a <div> inside that div.
#for data in contact.find_all('div', class_='infoMultiValue'):
# cardinfo['Description'].append( data.text)
print("---")
print(hubname)
print("---")
pprint(cardinfo)
it allways gives back the content information - but not the data that i am looking for - the text of the description: i am doing something wrong...
CodePudding user response:
Maybe this can give you a start. You HAVE to dig into the HTML to find the key markers for the information you want. I'm sensing that you want the title, and the contact information. The title is in an <h2> tag, the only such tag on the page. The contact info is within a <div class='hubCard'> tag, so we can grab that and pull out the pieces.
import requests
from bs4 import BeautifulSoup
from pprint import pprint
url = 'https://s3platform-legacy.jrc.ec.europa.eu/digital-innovation-hubs-tool/-/dih/1096/view'
r = requests.get(url)
soup = BeautifulSoup(r.text, 'html5lib')
# The name of the hub is in the <h2> tag.
hubname = soup.find('h2').text
# All contact info is within a <div class='hubCard'>.
contact = soup.find("div", class_="hubCard")
cardinfo = {}
# Grab all the <p> tags inside that div. The infoLabel class marks
# the section header.
for data in contact.find_all('p'):
if 'infoLabel' in data.attrs.get('class', []):
title = data.text
cardinfo[title] = []
else:
cardinfo[title].append( data.text )
# The contact info is in a <div> inside that div.
for data in contact.find_all('div', class_='infoMultiValue'):
cardinfo['Contact information'].append( data.text)
print("---")
print(hubname)
print("---")
pprint(cardinfo)
Output:
---
Bavarian Robotic Network (BaRoN) Bayerisches Robotik-Netzwerk, BaRoN
---
{'Contact information': [' Adam Schmidt',
' [email protected]',
' 49 (0)89 289-18064'],
'Coordinator (University)': ['',
'Robotic Competence Center of Technical '
'University of Munich, TUM CC'],
'Coordinator website': ['http://www6.in.tum.de/en/home/\n'
'\t\t\t\t\t\n'
'\t\t\t\t\t\n'
'\t\t\t\t\t'],
'Location': ['Schleißheimer Str. 90a, 85748, Garching bei München (Germany)'],
'Social Media': ['\n'
'\t\t\t\t\t\t\n'
'\t\t\t\t\t\t\t\t\t\t \n'
'\t\t\t\t\t\t\t\t\t\t\n'
'\t\t\t\t\t\t\t\t\t\t \n'
'\t\t\t\t\t\t\t\t\t\t\n'
'\t\t\t\t\t\t\t\t\t\t \n'
'\t\t\t\t\t\t\t\t\t\t\n'
'\t\t\t\t\t\t'],
'Website': ['http://www.robot.bayern'],
'Year Established': ['2017']}