I am interested in all of the visible text of a website.
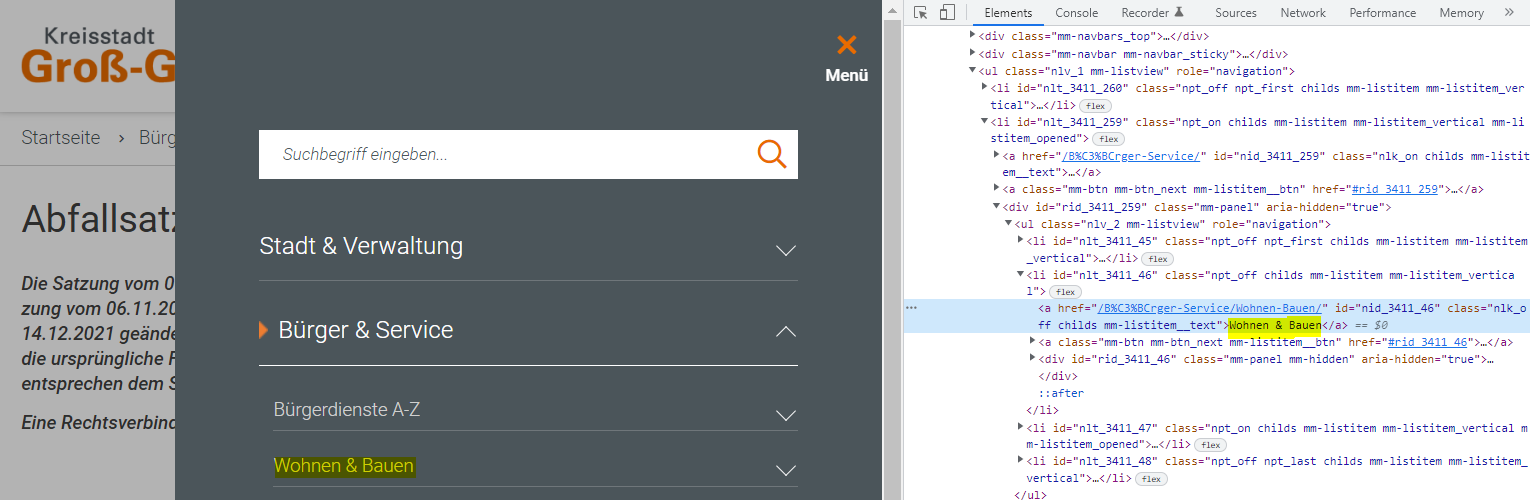
The only thing is: I would like to exclude hyperlink text. Thereby I am able to exlude text in menu bars because they often contain links. In the image you can see that everything from a menu bar could be excluded (e.g. "Wohnen & Bauen").
All in all my spider looks like this:
class MySpider(CrawlSpider):
name = 'my_spider'
start_urls = ['https://www.gross-gerau.de/Bürger-Service/Wohnen-Bauen/']
rules = (
Rule(LinkExtractor(allow="Bürger-Service", deny=deny_list_sm),
callback='parse', follow=True),
)
def parse(self, response):
item = {}
item['scrape_date'] = int(time.time())
item['response_url'] = response.url
# old approach
# item["text"] = " ".join([x.strip() for x in response.xpath("//text()").getall()]).strip()
# exclude at least javascript code snippets and stuff
item["text"] = " ".join([x.strip() for x in response.xpath("//*[name(.)!='head' and name(.)!='script']/text()").getall()]).strip()
yield item
The solution should work for other websites, too.Does anyone have an idea how to solve this challenge? Any ideas are welcome!
CodePudding user response:
You can extend your predicate as
[name()!='head' and name()!='script' and name()!='a']