I have a bunch of pdfs that display Cyrillic properly. But if I copy and paste texts from them, gibberish was produced.
Then I used the save as function from okular to convert the pdf to text file and find that the encoding is WINDOWS-1251, which is an old Cyrillic encoding. After converting it UTF-8, the Cyrillic is displayed properly.
A sample link of the file is 
poppler-22.04.0\Library\bin>pdftotext -layout -f 1 -l 1 -enc ISO-8859-9 encoded.pdf -
Response, first page attempt with just layout seems to show there are some coding issues, but its a rough programmatic output that perhaps could be improved via FnR or code tweaking
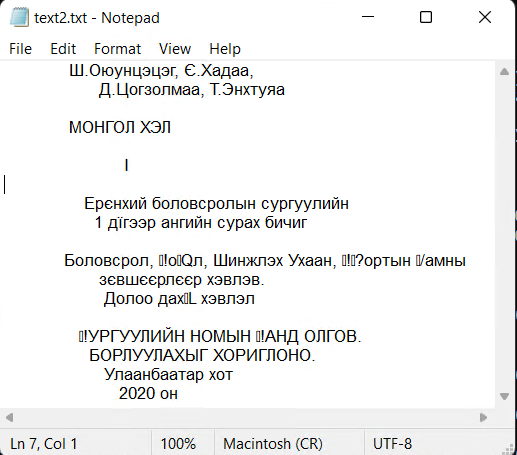
Ш.Оунццг, Є.Хадаа,
Д.Цогзолмаа, Т.нхтуяа
МОНГОЛ ХЛ
I
Еєнхий боловсолын сугуулийн
1 дїг ангийн суах бичиг
Боловсол, ол, Шинжлх Ухаан, отын амны
зєвшєєлєє хвлв.
Долоо дах хвлл
УГУУЛИЙН НОМЫН АНД ОЛГОВ.
БОЛУУЛАХЫГ ХОИГЛОНО.
Улаанбаата хот
2020 он
Alternative is try this as more valid characters but needs "de-spacing"
pdftotext -layout -f 1 -l 1 -enc UTF-16 encoded.pdf -
Ш . О ю у н ц э ц э г , Є . Х а д а а ,
Д . Ц о г з о л м а а , Т . Э н х т у я а
М О Н Г О Л Х Э Л
I
Е р є н х и й б о л о в с р о л ы н с у р г у у л и й н
1 д ї г э э р а н г и й н с у р а х б и ч и г
Б о л о в с р о л , ! оQ л , Ш и н ж л э х У х а а н , !? о р т ы н / а м н ы
з є в ш є є р л є є р х э в л э в .
Д о л о о д а хL х э в л э л
! У Р Г У У Л И Й Н Н О М Ы Н ! А Н Д О Л Г О В .
Б О Р Л У У Л А Х Ы Г Х О Р И Г Л О Н О .
У л а а н б а а т а р х о т
2 0 2 0 о н
De-spaced but still needs replace �! with C and �/ with Яetc.
note in both cases chcp 1251