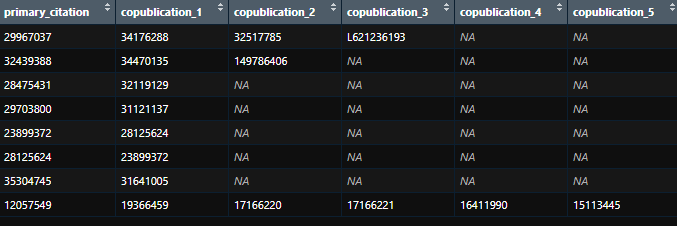
Each primary_citation may have multiple copublications. I would like to aggregate citation_id's associated with each primary citation. The following code works, but creates duplicate rows that must subsequently be removed. I'm looking for a way to avoid creating duplicate rows.
dat %>%
group_by(primary_citation) %>%
mutate(copublications = paste0(citation_id, collapse = ", ")) %>%
ungroup() %>%
select(-citation_id)
dat <- structure(list(primary_citation = c("29967037", "32439388", "32439388",
"28475431", "29967037", "29703800", "29967037", "23899372", "28125624",
"35304745", "12057549", "12057549", "12057549", "12057549", "12057549"
), citation_id = c("34176288", "34470135", "149786406", "32119129",
"32517785", "31121137", "L621236193", "28125624", "23899372",
"31641005", "19366459", "17166220", "17166221", "16411990", "15113445"
)), row.names = c(NA, -15L), class = c("tbl_df", "tbl", "data.frame"
))
CodePudding user response:
Lmk if is that what you needs:
dat %>%
group_by(primary_citation) %>%
mutate(N = paste0("copublication_",row_number())) %>%
ungroup() %>%
pivot_wider(
id_cols = primary_citation,
names_from = N,
values_from = !c(primary_citation, N),
values_fill = NA)