I am trying to understand the behavior of large numbers when casted with Float Data type in spark.
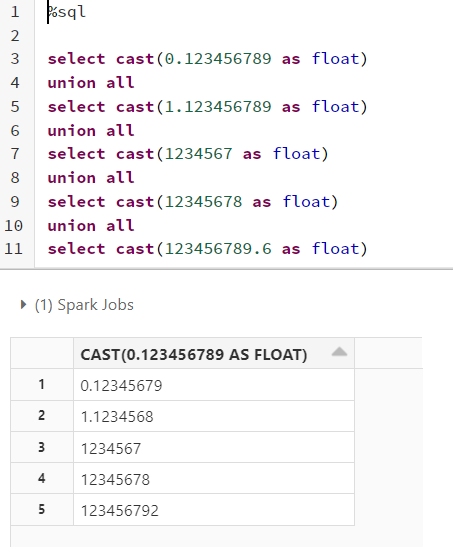
Last select statement in the above picture gives very abrupt output.
Thanks in Advance !
CodePudding user response:
The output is not abrupt. It is simply a demonstration of the limitation of the truncated floating-point representation. FloatType in Spark is backed by Java's float - 32-bit IEEE754 floating-point number. It has 24 bits for the significand, but the MSB is always 1 and hence the actual precision is only 23 bits.
123456789.6 is 1.8396495223045348... x 226. 1.8396495223045348 is 1.110101101111001101000101011001... in binary. Limiting it to only 24 bits results in 1.11010110111100110100011 (the last bit is rounded up), which is 1.8396495580673218 in decimal. Multiply it by 226 and you get 123456792.