I have a CSV data like the below:
time_value,annual_salary
5/01/19 01:02:16,120.56
06/01/19 2:02:17,12800
7/01/19 03:02:18,123.00
08/01/19 4:02:19,123isdhad
I want to consider only numeric values along with decimal values. Basically, I want to ignore the last record since it is alphanumeric in the case of annual_salary and which I was able to do so. But, when I tried it convert it to the proper decimal values it is giving me incorrect results. Below is my code:
df = df.withColumn("annual_salary", regexp_replace(col("annual_salary"), "\.", ""))
df = df.filter(~col("annual_salary").rlike("[^0-9]"))
df.show(truncate=False)
df.withColumn("annual_salary", col("annual_salary").cast("double")).show(truncate=False)
But it gives me records like the below:
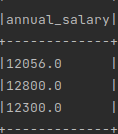
which is incorrect.
Expected output:
annual_salary
120.56
12800.00
123.00
What could be wrong here? Should I need to implement UDF for this type of conversion?
CodePudding user response:
Please Try cast Decimal Type.
df.where(~col('annual_salary').rlike('[A-Za-z]')).withColumn('annual_salary', col('annual_salary').cast(DecimalType(38,2))).show()
---------------- -------------
| time_value|annual_salary|
---------------- -------------
|5/01/19 01:02:16| 120.56|
|06/01/19 2:02:17| 12800.00|
|7/01/19 03:02:18| 123.00|
---------------- -------------