I have a dataframe containing sentences taken from a chapter of a book, each one annotated with an emotion (Anger, sadness, etc). The result is something like this:
d = {'text': ["aaa", "aaa", "bbb", "aaa", "bbb", "bbb"],
'start': [0, 1, 0, 2, 1, 0],
'end': [250, 500, 501, 251, 249, 499]},
'label': ["anger", "sadness", "sadness", "sadness", "anger", "anger"],
'annotator': [0,1,1,1,0,0],
'original_data': ["aaaaaa", "bbbbbb", "aaaaaa", "bbbbbb", "aaaaaa", "bbbbbb"],
'speaker': ["Achiles", "Hektor", "Achiles", "Achiles", "Hektor", "Hektor"],
'rounded_length': [110, 250, 250, 110, 110, 250]}
df = pd.DataFrame(data=d)
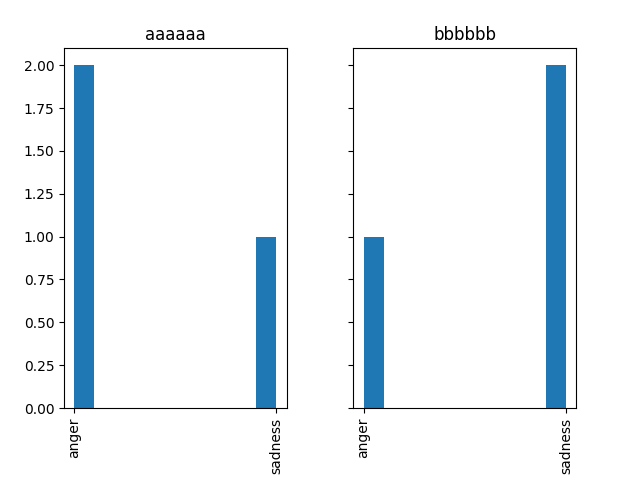
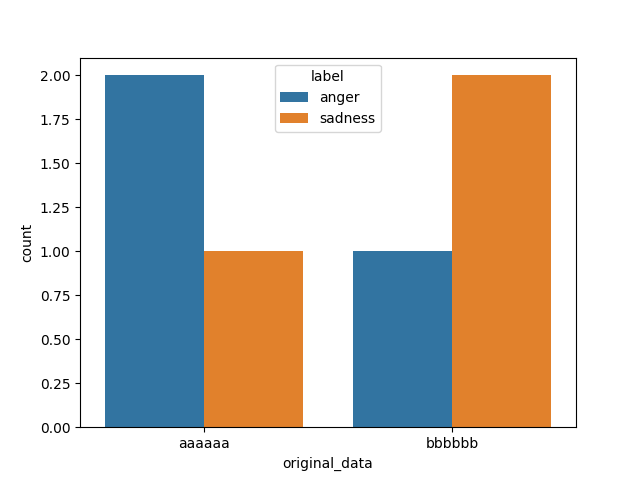
Edit: if you want all histograms on a shared axis, you can use seaborn:
import seaborn as sns
sns.countplot(data=df, x='original_data', hue='label')
CodePudding user response:
You could do it with pandas plots in this way:
(df.groupby(["label", "original_data"])
# We just need the count, so take text to count entries in there
.text.count()
# Unstack to make columns out of this
.unstack("original_data")
.plot.bar());
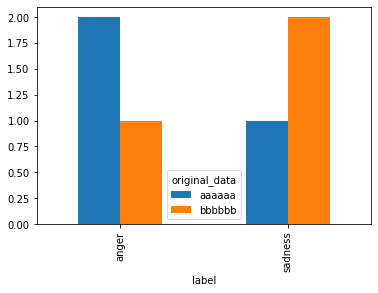
The idea here is to first look at the groupby operation and make sure you get a dataframe result that will plot well! In this case I used unstack to make columns out of the facet that I wanted to have in different colors (hues).
Personally I think these kinds of plots are easier to create in seaborn.