I have an Excel file that I need to read in python. The row needs to be read for each columns in the same way, for all the references in that row.
For instance: In column C, contains 2 references, I need a code or loop to function in such a way that date, id, amount and weight should be same for the first Reference. and also for the second reference, since it is the same date id , amount and weight only reference is different. After that only the loop should go to next row.
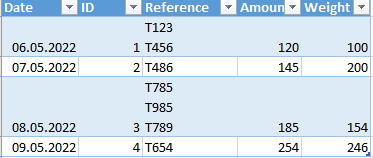
The result should see somehow this way ;
Date ID References Amount Weight
06.05.2022 1 T123 120 100
06.05.2022 1 T456 120 100
07.05.2022 2 T486 145 200
08.05.2022 3 T785 185 154
08.05.2022 3 T985 185 154
08.05.2022 3 T789 185 154
09.05.2022 4 T654 254 246
See this screenshot:
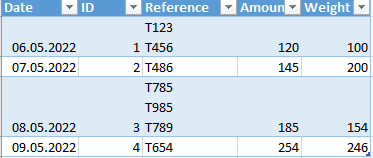
Could you help me to find the right code for this in python?
CodePudding user response:
With this as my spreadsheet:
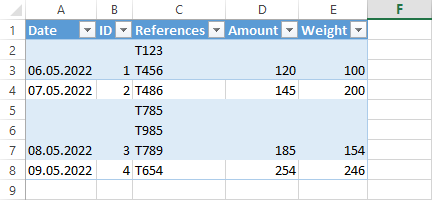
If you don't care about losing the formatting in your spreadsheet, you can use 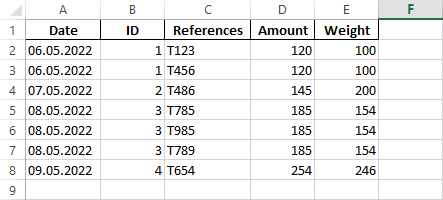
import os
import pandas as pd
filename = r"spreadsheet.xlsx"
new_filename = r"spreadsheet_with_all_holes_backfilled_by_pandas.xlsx"
# Read the spreadsheet into a dataframe
df = pd.read_excel(filename)
# Backfill the holes. inplace=True means it updates the existing dataframe
df.bfill(inplace=True)
# Save the spreadsheet
df.to_excel(new_filename, index=False)
# Launch the new spreadsheet
os.startfile(new_filename)
If you want to keep the formatting, you can use 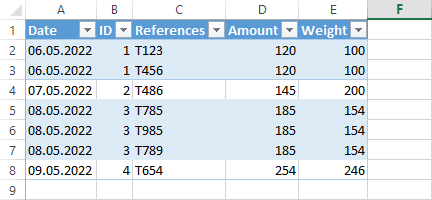
import os
import openpyxl
filename = r"spreadsheet.xlsx"
new_filename = r"spreadsheet_with_all_holes_filled_by_openpyxl.xlsx"
# Load the spreadsheet file
wb = openpyxl.load_workbook(filename)
# Get the currently active sheet
ws = wb.active
# Loop over every column in the sheet
for column in ws.iter_cols():
# Reset the value each new column
last_valid_value = None
# Then over every cell, starting from the bottom, heading up
for cell in reversed(column):
# Read the cell's value. We know it was empty if its value is None. If
# so, update its value with the last valid value (which has come from
# below in the spreadsheet), otherwise update the last_valid_value.
value = cell.value
if value is None:
cell.value = last_valid_value
else:
last_valid_value = value
# Save the spreadsheet
wb.save(new_filename)
# Launch the new spreadsheet
os.startfile(new_filename)
CodePudding user response:
You can update the columns of the data like this after importing
data = pd.read_excel(excel_data)
data.set_axis(['Date ID', 'References', 'Amount', 'Weight'], axis='columns')