I am working on a survey and the data looks like this:
ID Q1 Q2 Q3 Gender Age Dep Ethnicity
001 Y N Y F 22 IT W
002 N Y Y M 35 HR W
003 Y N N F 20 IT A
004 Y N Y M 54 OPRE B
005 Y N Y M 42 OPRE B
Now, I'd like to add two indexes Dep and Gender to create a table like:
Question Dep Response #M #F %M %F
Q1 IT Y 0 2 0 100
IT N 0 0 0 0
HR Y 0 0 0 0
HR N 1 0 100 0
OPRE Y 2 0 100 0
OPRE N 0 0 0 0
Q2 IT Y 0 0 0 0
IT N 0 2 0 100
HR Y 1 0 100 0
HR N 0 0 0 0
OPRE Y 0 0 0 0
OPRE N 2 0 100 0
Q3 ......
My codes are like this:
df2=df[['ID','Gender','Dep', 'Q1', 'Q2', 'Q3' ]].melt(
['ID','Gender', 'Dep'], var_name='question', value_name='response').pivot_table(
index=[ 'question','Dep','response'],
columns='Gender',
values='ID', aggfunc='count').fillna(0)
If I have more questions, I don't want to copy and paste all the Qs in the dataframe, instead I'd like to have a loop which can go over all the questions. Can anyone help?
CodePudding user response:
IIUC, you can use pd.wide_to_long:
out = (pd.wide_to_long(df, stubnames='Q', i=['ID', 'Dep', 'Ethnicity'], j='Question')
.reset_index().rename(columns={'Q': 'Response'}).assign(Count=1)
.pivot_table('Count', ['Question', 'Dep', 'Response'], 'Gender',
fill_value=0, aggfunc='count'))
Output:
>>> out
Gender F M
Question Dep Response
1 HR N 0 1
IT Y 2 0
OPRE Y 0 2
2 HR Y 0 1
IT N 2 0
OPRE N 0 2
3 HR Y 0 1
IT N 1 0
Y 1 0
OPRE Y 0 2
CodePudding user response:
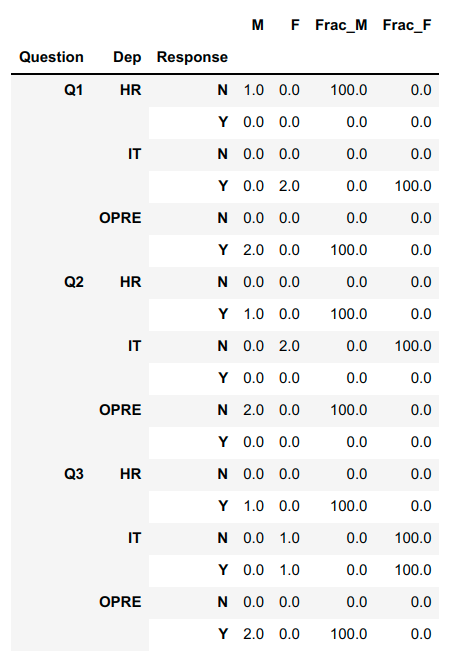
Here's a way to keep the 0 rows by melting to long form as you're doing, converting the Response to a pd.Categorical, and then groupbing and aggregating
import pandas as pd
df = pd.DataFrame({
'ID': [1, 2, 3, 4, 5],
'Q1': ['Y', 'N', 'Y', 'Y', 'Y'],
'Q2': ['N', 'Y', 'N', 'N', 'N'],
'Q3': ['Y', 'Y', 'N', 'Y', 'Y'],
'Gender': ['F', 'M', 'F', 'M', 'M'],
'Age': [22, 35, 20, 54, 42],
'Dep': ['IT', 'HR', 'IT', 'OPRE', 'OPRE'],
'Ethnicity': ['W', 'W', 'A', 'B', 'B'],
})
#melt to long form
long_df = df.melt(
id_vars=['ID','Gender','Age','Dep','Ethnicity'],
var_name='Question',
value_name='Response',
)
#convert Gender/Response to categorical to keep 0's
long_df['Response'] = pd.Categorical(long_df['Response'])
#groupby Q/Dep/Response and agg to get M/F/Frac_M/Frac_F
agg_df = long_df.groupby(['Question','Dep','Response']).agg(
M = ('Gender', lambda g: g.eq('M').sum()),
F = ('Gender', lambda g: g.eq('F').sum()),
Frac_M = ('Gender', lambda g: g.eq('M').sum()/len(g)*100),
Frac_F = ('Gender', lambda g: g.eq('F').sum()/len(g)*100),
).fillna(0)
print(agg_df)