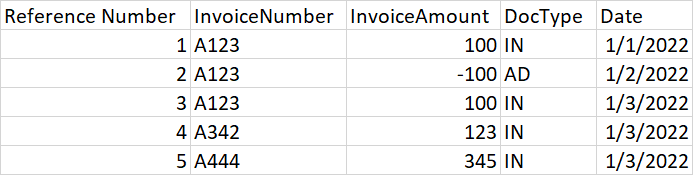
I'm trying to identify duplicate invoices. In my dataset, I have instances where there are correction that are causing me to identify false positives. I would like to figure out a way to net correction and only return the final invoice.
In my example the first 3 transactions are all related. I would like to write something using pandas that will identify that the first two lines net out and only leaves 3rd line.
Code to Create the table
df = pd.DataFrame({'Reference Number': {0: 1, 1: 2, 2: 3, 3: 4, 4: 5},
'InvoiceNumber': {0: 'A123', 1: 'A123', 2: 'A123', 3: 'A342', 4: 'A444'},
'InvoiceAmount': {0: 100, 1: -100, 2: 100, 3: 123, 4: 345},
'DocType': {0: 'IN', 1: 'AD', 2: 'IN', 3: 'IN', 4: 'IN'},
'Date': {0: '1/1/2022',
1: '1/2/2022',
2: '1/3/2022',
3: '1/3/2022',
4: '1/3/2022'}})
What I would want the table to look like when finished:

CodePudding user response:
The relation between different invoices are not clear.
It could be simply:
>>> df.drop_duplicates('InvoiceNumber', keep='last')
Reference Number InvoiceNumber InvoiceAmount DocType Date
2 3 A123 100 IN 1/3/2022
3 4 A342 123 IN 1/3/2022
4 5 A444 345 IN 1/3/2022