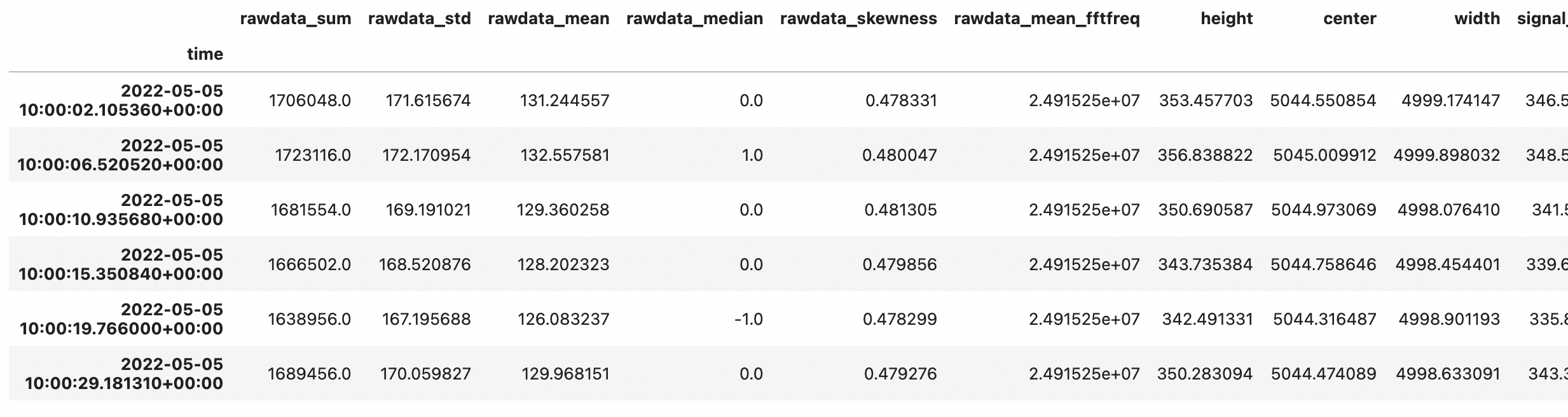
I have time-series data in a HDF file. When I load this file I get a Pandas DataFrame like this:
DateTimeIndex | col 1 (float) | ... | col N (float) | dict_col (dict)
The dictionary in dict_col contains data structured like a normal dictionary:
{'field1': value1 (float), ..., 'fieldN': valueN (float)}
How can I convert the initial DataFrame in a DataFrame structured like this?:
DateTimeIndex | col 1 (float) | ... | col N (float) | field1 (float) | ... | floatN (float)
Currently, my code looks lie this:
data = DataFrame(pd.read_hdf('the_hdf_file.h5'))
out_frame = DataFrame() # output DataFrame
for column in data.columns:
if column != 'dict_col':
out_frame = pd.concat([out_frame, data[column]], axis=1)
else:
sub_set = data[column]
for value in sub_set.items():
item_series = Series(value[0])
item_series = item_series.rename({0: 'time'})
item_series = pd.concat([item_series, Series(value[1])])
out_frame = pd.concat([out_frame, item_series], axis=1)
... manipulations with out_frame ...
But this code is utterly slow. How can I do this in a more efficient way?
EDIT: provided 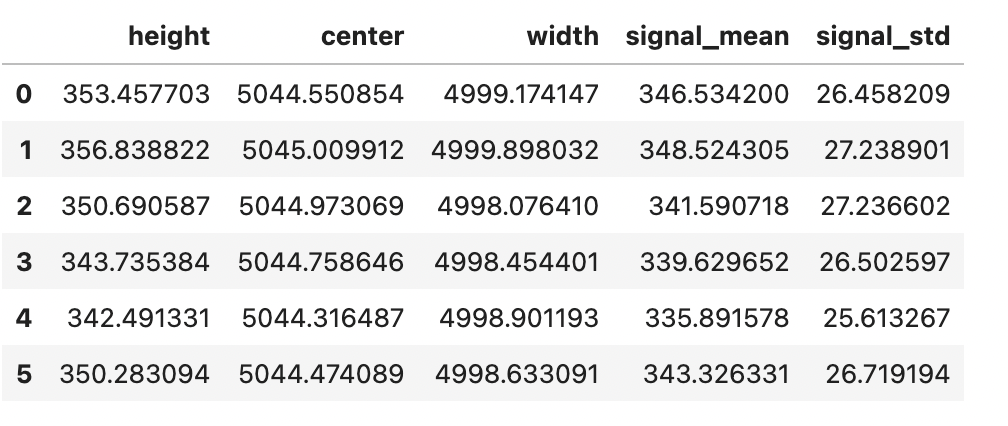
To merge new columns use:
data = pd.DataFrame(pd.read_hdf('test_data_20220720.h5'))
new = pd.DataFrame.from_records(data.rawdata_boxfit)
new.index = data.index
pd.concat([data, new], axis=1).drop('rawdata_boxfit', axis=1)