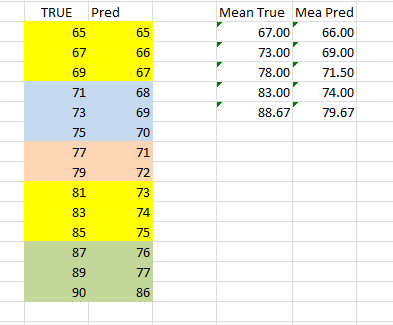
I have a dataframe with two columns 'True' and 'Pred'. The 'True' column has values between 65 to 90. I want to take the mean for both columns based on an interval in the 'True' column ranging between 65 to 70, 71 to 75, 76 to 80, 81 to 85, and 86 to 90. So my final dataframe should have five values in the True Column and five values in Pred Columns.
What is the easy way to do this in python? I have given the data and the output which is required with this query.
CodePudding user response:
You can combine pd.cut with groupby:
import pandas as pd
df = pd.DataFrame({
"TRUE": [65, 67, 69, 71, 73, 75, 77, 79, 81, 83, 85, 87, 89, 90],
"Pred": [65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 86]
})
df.groupby(pd.cut(df["TRUE"], bins=[65-1e-10, 70, 75, 80, 85, 90], labels=[0, 1, 2, 3, 4]))["Pred"].mean().round(2)
Output:
TRUE
0 66.00
1 69.00
2 71.50
3 74.00
4 79.67
Name: Pred, dtype: float64
pd.cut segements your data into categories (defined by the labels argument) according to bins. If you, for instance, consider the first two values of your bins argument, [65-1e-10, 70, ..] all TRUE values that are in that interval (65-1e-10, 70] (left-open, right-closed) are mapped to 0. This series can then be used in the groupby statement to aggregate the segments by their means.
You can also make the intervall left-closed and right-open:
df.groupby(pd.cut(df["TRUE"], bins=[65, 71, 76, 81, 86, 91], labels=[0, 1, 2, 3, 4], right=False, include_lowest=True))[["TRUE", "Pred"]].mean().round(2).rename_axis(None, axis=0)
Output:
TRUE Pred
0 67.00 66.00
1 73.00 69.00
2 78.00 71.50
3 83.00 74.00
4 88.67 79.67