I have many texts file with the given format (It won’t be exactly this format line by line; I am showing some parts from one file to understand the general format).
C:\seismo\2008\07\2008-07-03-2055-56S.HP____030
2008 7 3205556 BNJR tc 16.1 f 1.5 s/n 4.0 Q 101 corr -0.89 rms 0.18
2008 7 3205556 BNJR tc 16.1 f 3.0 s/n 2.9 Q 290 corr -0.80 rms 0.20
2008 7 3205556 BNJR tc 16.1 f 8.0 s/n 3.9 Q 695 corr -0.63 rms 0.37
2008 7 3205556 BNJR tc 16.1 f 12.0 s/n 8.1 Q 913 corr -0.67 rms 0.39
2008 7 3205556 BNJR tc 16.1 f 16.0 s/n 5.7 Q 1435 corr -0.58 rms 0.42
C:\seismo\2008\07\2008-07-03-2055-56S.HP____030
2008 7 3205556 BNJR tc 16.1 f 1.5 s/n 7.9 Q 150 corr -0.78 rms 0.19
2008 7 3205556 BNJR tc 16.1 f 3.0 s/n 5.3 Q 190 corr -0.86 rms 0.24
2008 7 3205556 BNJR tc 16.1 f 5.0 s/n 2.3 Q 401 corr -0.64 rms 0.39
2008 7 3205556 BNJR tc 16.1 f 8.0 s/n 3.1 Q 673 corr -0.65 rms 0.37
2008 7 3205556 BNJR tc 16.1 f 16.0 s/n 3.8 Q 1320 corr -0.64 rms 0.39
C:\seismo\2008\07\2008-07-24-1124-44S.HP____012
C:\seismo\2008\07\2008-07-24-1124-44S.HP____012
2008 724112444 BNJR tc 9.3 f 1.5 s/n 2.7 Q 119 corr -0.82 rms 0.21
2008 724112444 BNJR tc 9.3 f 3.0 s/n 2.3 Q 286 corr -0.68 rms 0.29
C:\seismo\2008-10-21-1507-30S.__053
C:\seismo\2008-10-21-1544-56S.__033
C:\seismo\2008-10-21-1544-56S.__033
C:\seismo\2008-10-21-1544-56S.__033
C:\seismo\2008-10-21-1742-39S.NSN___015
C:\seismo\2008-10-21-1742-39S.NSN___015
C:\seismo\2010-11-18-1111-12S.NSN___027
20101118111112 BNJR tc 20.2 f 1.5 s/n 2.6 Q 141 corr -0.79 rms 0.20
20101118111112 BNJR tc 20.2 f 3.0 s/n 6.6 Q 292 corr -0.58 rms 0.37
20101118111112 BNJR tc 20.2 f 5.0 s/n 3.4 Q 894 corr -0.54 rms 0.23
C:\seismo\2011-02-01-2130-40S.NSN___027
C:\seismo\2011-02-04-0333-36S.NSN___027
C:\seismo\2011-02-04-0333-36S.NSN___027
Which is showing the file path of certain files with their content in it, if the file doesn’t have required content, it only shows the path of the file.
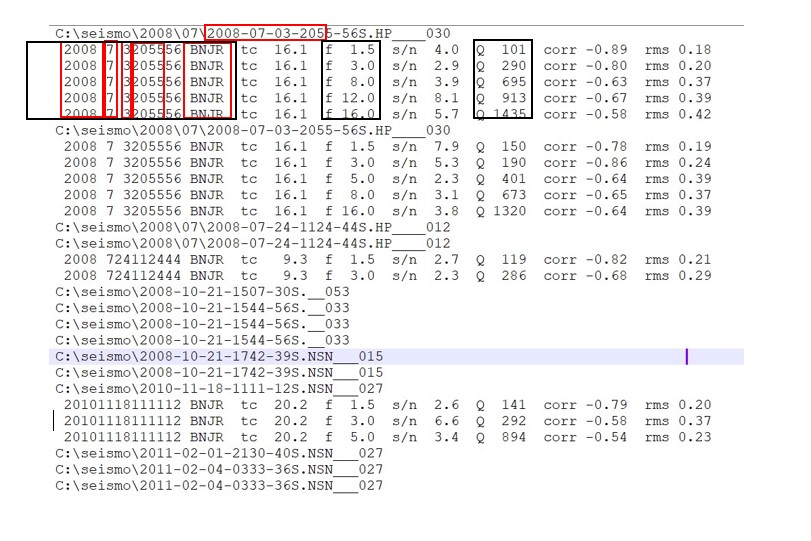
The information (variables) I have marked with a red rectangle is the key information I have to search for whether the file is not listed in the above file or not. If it is listed, the content needs to extract too. I am looking for a way to extract the path and its content shown in the file respective to the information I have (red rectangle). While extracting the content I want to specifically extract the columns marked with black rectangle.
I made a function to extract lines/multiple lines with respect to a line containing specific string. Since the content following each path has different number of lines this function seems useless in my problem.
def extract_lines(file,linenumbers,endline=None):
'''Extract a line /multiple lines from a text file
line number should be considered as starting from zero.
'''
with open(file, encoding='utf8') as f:
content = f.readlines()
lines=[]
if ((type(linenumbers) is int) or (all([isinstance(item, int) for item in linenumbers]))):
if type(linenumbers) is list:
for idx,item in enumerate(linenumbers):
lines.append(content[item])
elif ((endline is None) and (type(linenumbers) is int)):
lines.append(content[linenumbers])
elif ((type(endline) is int) and (type(linenumbers) is int)):
for item in np.arange(linenumbers,endline):
lines.append(content[item])
else:
print('Error in linenumbers input')
lines=[s.replace('\t',' ') for s in lines]
lines=[s.strip('\n') for s in lines]
return lines
How to perform with this task using python?
CodePudding user response:
This file has fixed columns, so you need to fetch your data using column numbers.
#0123456789-123456789-123456789-123456789-123456789-123456789-123456789-123456789-
# 2008 7 3205556 BNJR tc 16.1 f 1.5 s/n 4.0 Q 101 corr -0.89 rms 0.18
for ln in open('x.txt'):
# Is this a file line or a data line?
if ln[1] != ' ':
curfile = ln.strip()
else:
# Grab date and time.
dt = ln[2:14].replace(' ','0')
# Grab the 2-digit code.
dc = ln[14:16]
# Grab site code
site = ln[17:21]
# Grab the 'f' code.
f = float(ln[34:39].strip())
# Grab the 'Q' code.
q = int(ln[52:56].strip())
print(f"{dt},{dc},{site},{f},{q}")
Output:
200807032055,56,BNJR,1.5,10
200807032055,56,BNJR,3.0,29
200807032055,56,BNJR,8.0,69
200807032055,56,BNJR,12.0,91
200807032055,56,BNJR,16.0,143
200807032055,56,BNJR,1.5,15
200807032055,56,BNJR,3.0,19
200807032055,56,BNJR,5.0,40
200807032055,56,BNJR,8.0,67
200807032055,56,BNJR,16.0,132
200807241124,44,BNJR,1.5,11
200807241124,44,BNJR,3.0,28
201011181111,12,BNJR,1.5,14
201011181111,12,BNJR,3.0,29
201011181111,12,BNJR,5.0,89
CodePudding user response:
Its hard to tell from the data posted, but I think this is tab separated data. The first column either has a file name or is empty. You want to group the data without a file name with the file name above it. itertools.groupby can do this. Have it start a new group on each non-empty first column. As a note, you could do this in pandas also by using its read_csv and its groupby method.
In the example, I put the groupby code in a generator function. This makes it usable in more than one place and reduces nesting. Alternately, you could replace the yield with your own code and skip the extra function.
import itertools
import csv
def extract_records(filename):
"""Yield (filename, list_of_rows) pairs from file"""
found_filename = None
with open(filename, encoding="utf8", newline="") as file:
reader = csv.reader(file, dialect="excel-tab")
for is_filename, rows in itertools.groupby(reader,
lambda row: not row[0].strip()):
if is_filename:
found_filename = list(rows)[0][0] # only row, first column
else:
assert found_filename is not None, "filename precedes values"
yield found_filename, list(rows)
for filename, values in extract_records("test.txt"):
print(filename, values)