I want to match a1 a2 from the row whose a3 is missing with the entire column of b1 b2 b3 where ever a1 a2 matches with any two b's value we will grab the 3rd b value i.e in row 2 a1=84 and a2=5 which is a match for b's in row 3 where b1=5 and b2=84 so now we will grab the value b3=89 in this case. Similarly for row 5 we will grab the value of b2=66.
this is just a small data set actual data contains millions of rows.
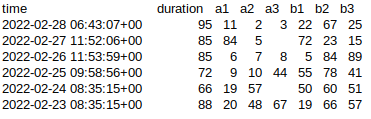
| time | duration | a1 | a2 | a3 | b1 | b2 | b3 |
|---|---|---|---|---|---|---|---|
| 2022-02-28 | 95 | 11 | 2 | 3 | 22 | 67 | 25 |
| 2022-02-27 | 85 | 84 | 5 | 72 | 23 | 15 | |
| 2022-02-26 | 87 | 6 | 7 | 8 | 5 | 84 | 89 |
| 2022-02-25 | 72 | 9 | 10 | 44 | 55 | 78 | 41 |
| 2022-02-24 | 66 | 19 | 57 | 50 | 60 | 51 | |
| 2022-02-23 | 88 | 20 | 48 | 67 | 19 | 66 | 57 |
CodePudding user response:
You can get all permutations of b columns, left join with original DataFrame filtered only rows with missing values in a3 for a3_ column wich match a1, a2 in list. Then join list to one Series, remove possible duplicates in index and replace missing values of a3 column in original DataFrame:
from itertools import permutations
cols = ['b1','b2','b3']
L = [df[df['a3'].isna()].merge(df.loc[:, x].set_axis(['a1','a2','a3'], axis=1),
how='left', on=['a1','a2'], suffixes=('','_'))['a3_'].dropna()
for x in permutations(cols, 3)]
final = pd.concat(L)
final = final[~final.index.duplicated()]
print (final)
4 66.0
1 89.0
Name: a3_, dtype: float64
df['a3'] = df['a3'].fillna(final)
print (df)
time duration a1 a2 a3 b1 b2 b3
0 2022-02-28 95 11 2 3.0 22 67 25
1 2022-02-27 85 84 5 89.0 72 23 15
2 2022-02-26 87 6 7 8.0 5 84 89
3 2022-02-25 72 9 10 44.0 55 78 41
4 2022-02-24 66 19 57 66.0 50 60 51
5 2022-02-23 88 20 48 67.0 19 66 57
CodePudding user response:
I use to code algorithm by hand trying to be readable and understandable.
Here is an old geek fashion code with the following algoritm:
if a1,a2 are in b1,b2,b3 respective products are a1a2 and a1a2the third element.
the thirdElement is exactly b1b2b3//a1a2 if the remainder is 0. (notice integer division).
As a1a2 can be equal to several bxby , check too that a1 a2 == bx by (where bx by is (b1 b2 b3 - third element) ).
(a3 is set to None here, could be "" depending of your data )
tests = [ \
["2022-02-28",95,11,2,3,22,67,25],\
["2022-02-27",85,84,5,None,72,23,15],\
["2022-02-26",87,6,7,8,5,84,89],\
["2022-02-25",72,9,10,44,55,78,41],\
["2022-02-24",66,19,57,None ,50,60,51],\
["2022-02-23",88,20,48,67,19,66,57]\
]
# first collect products and sums of all b
storeb1b2b3 =[]
storesumb1b2b3 = []
for test in tests:
storeb1b2b3.append(test[5]*test[6]*test[7])
storesumb1b2b3.append(test[5] test[6] test[7])
# now loop on a1 a2 and check in all b
for ia in range(0,len(tests)):
test = tests[ia]
# check a3 empty
if (test[4] != None):
continue
a1= test[2]
a2 = test[3]
a1a2 =a1*a2
# check against all b
for ib in range(0,len(storeb1b2b3)):
b1b2b3= storeb1b2b3[ib]
sumb1b2b3 = storesumb1b2b3[ib]
if (b1b2b3 % a1a2 == 0):
candidate =(b1b2b3//a1a2)
if ((sumb1b2b3 - candidate) == (a1 a2)):
print ( "for",a1,a2,"at",tests[ia][0],"found: ",candidate, "at ",tests[ib])
Notes :
products and sum of b are calculated once at begining to optimize. If a too long list to be stored, can be calculated on the fly in a1a2 loops.
Use indices ia, ib to be able to print source lines.
for 84 5 at 2022-02-27 found: 89 at ['2022-02-26', 87, 6, 7, 8, 5, 84, 89]
for 19 57 at 2022-02-24 found: 66 at ['2022-02-23', 88, 20, 48, 67, 19, 66, 57]
Hope you enjoy coding too :)