I have a data frame data that looks like the below:
data <- structure(list(ID = c("POTR_001341", "POTR_001341", "POTR_156376",
"POTR_001106", "POTR_001178", "POTR_001178", "POTR_234156", "POTR_234156",
"POTR_003709", "POTR_003709", "POTR_006406", "POTR_006406", "POTR_233767",
"POTR_233767"), label = c("non", "co", "co", "non", "non", "co",
"co", "non", "co", "non", "non", "co", "co", "non"), num = c(20,
2, 16, 8, 1, 1, 8, 2, 3, 3, 25, 3, 7, 7)), row.names = c(NA,
-14L), class = "data.frame")
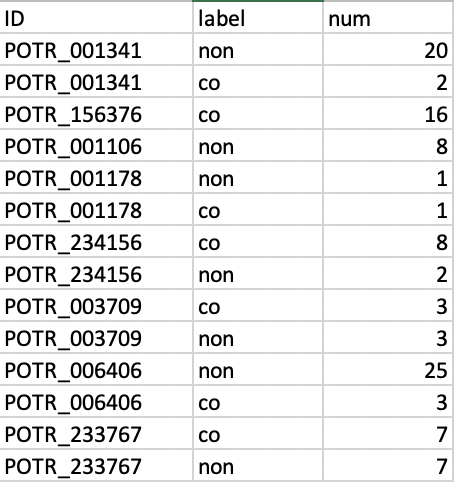
I want to create a 4th column based on information present in the three columns.
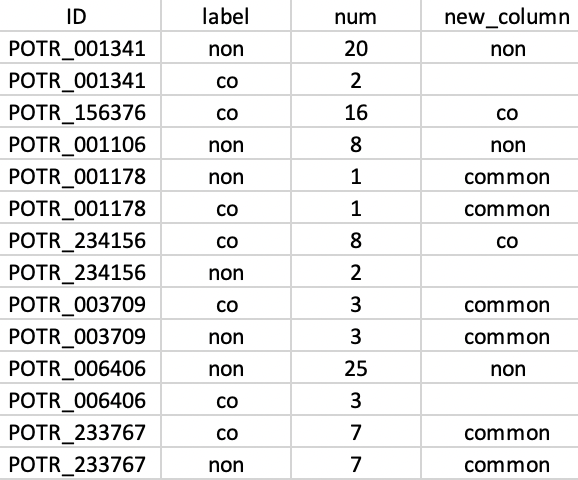
If the ID is a duplicate like POTR_001341 check the label which has bigger num and give its label in the new_column and other as empty. It should look like below:

If the ID is not a duplicate, give the label in the new_column.

If the ID has a duplicate and both the labels non and co have the same digits in the column num, then give common in the new_column. It should look like

So, the final output should look like:
CodePudding user response:
data <- structure(list(ID = c("POTR_001341", "POTR_001341", "POTR_156376",
"POTR_001106", "POTR_001178", "POTR_001178", "POTR_234156", "POTR_234156",
"POTR_003709", "POTR_003709", "POTR_006406", "POTR_006406", "POTR_233767",
"POTR_233767"), label = c("non", "co", "co", "non", "non", "co",
"co", "non", "co", "non", "non", "co", "co", "non"), num = c(20,
2, 16, 8, 1, 1, 8, 2, 3, 3, 25, 3, 7, 7)), row.names = c(NA,
-14L), class = "data.frame")
library(dplyr, warn = FALSE)
#> Warning: package 'dplyr' was built under R version 4.1.2
data %>%
group_by(ID) %>%
mutate(new_column = case_when(n() > 1 && all(num == first(num)) ~ 'common',
num == max(num) ~ label,
TRUE ~ ''))
#> # A tibble: 14 × 4
#> # Groups: ID [8]
#> ID label num new_column
#> <chr> <chr> <dbl> <chr>
#> 1 POTR_001341 non 20 "non"
#> 2 POTR_001341 co 2 ""
#> 3 POTR_156376 co 16 "co"
#> 4 POTR_001106 non 8 "non"
#> 5 POTR_001178 non 1 "common"
#> 6 POTR_001178 co 1 "common"
#> 7 POTR_234156 co 8 "co"
#> 8 POTR_234156 non 2 ""
#> 9 POTR_003709 co 3 "common"
#> 10 POTR_003709 non 3 "common"
#> 11 POTR_006406 non 25 "non"
#> 12 POTR_006406 co 3 ""
#> 13 POTR_233767 co 7 "common"
#> 14 POTR_233767 non 7 "common"
Created on 2022-08-22 by the reprex package (v2.0.1.9000)
CodePudding user response:
We may use
library(dplyr)
data %>%
group_by(ID) %>%
mutate(label = reorder(label, num),
new_column = if(n_distinct(num) == 1 & n_distinct(label) > 1) 'common'
else first(label),
new_column = replace(new_column, duplicated(new_column) &
new_column != 'common', "")) %>%
ungroup
-output
# A tibble: 14 × 4
ID label num new_column
<chr> <fct> <dbl> <chr>
1 POTR_001341 non 20 "non"
2 POTR_001341 co 2 ""
3 POTR_156376 co 16 "co"
4 POTR_001106 non 8 "non"
5 POTR_001178 non 1 "common"
6 POTR_001178 co 1 "common"
7 POTR_234156 co 8 "co"
8 POTR_234156 non 2 ""
9 POTR_003709 co 3 "common"
10 POTR_003709 non 3 "common"
11 POTR_006406 non 25 "non"
12 POTR_006406 co 3 ""
13 POTR_233767 co 7 "common"
14 POTR_233767 non 7 "common"