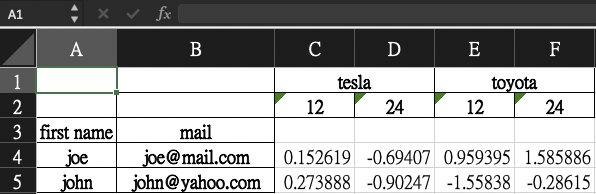
I have been trying to convert a multi-index pandas dataframe to the excel format (below) without success. I have tried using a pivot (and group by) for the multi-indexing, but in each case cannot get the number series (price) to augment to a single row without splitting out the dataframe and doing it manually ... "first name" and "mail" could be many columns with repeating rows, each for the car, term and price. Ideally, I need to see a row for each "client" with a series of prices under the index levels as headers.
arrays = [
["tesla", "tesla", "toyota", "toyota"],
["12", "24", "12", "24"],
]
tuples = list(zip(*arrays))
index = pd.MultiIndex.from_tuples(tuples, names=('Car', 'Term'))
df1 = pd.DataFrame(np.random.randn(4,1), index=index)
df1['name']='joe'
df1['email']='[email protected]'
df2 = pd.DataFrame(np.random.randn(4,1), index=index)
df2['name']='john'
df2['email']='[email protected]'
df3 = pd.concat([df1, df2])
df3.columns = ['price', 'first name', 'mail']
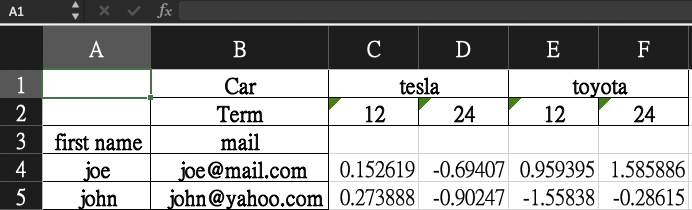
# Output =>
price first name mail
Car Term
tesla 12 0.181242 joe [email protected]
24 -1.292235 joe [email protected]
toyota 12 -1.446640 joe [email protected]
24 1.119652 joe [email protected]
tesla 12 -0.101694 john [email protected]
24 -0.980943 john [email protected]
toyota 12 -1.004959 john [email protected]
24 1.737056 john [email protected]
# Desired =>
tesla toyota
term term
first name mail 12 24 12 24
joe [email protected] 0.181242 -1.292235 -1.44664 1.119652
john [email protected] -0.101694 -0.980943 -1.004959 1.737056
CodePudding user response:
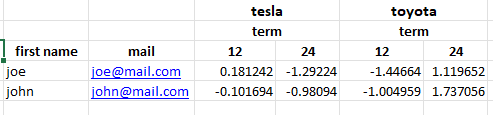
Closer but not exactly like your desire since Term is one of MultiIndex names from columns,
df3.reset_index(inplace=True)
df4 = df3.pivot(index=['first name', 'mail'], columns=['Car','Term'], values='price')
df4.to_excel('test.xlsx', merge_cells=True)
You can check
print(df4.columns)
Output:
MultiIndex([( 'tesla', '12'),
( 'tesla', '24'),
('toyota', '12'),
('toyota', '24')],
names=['Car', 'Term'])
As you might guess,
print(df4.index)
Output
MultiIndex([( 'joe', '[email protected]'),
('john', '[email protected]')],
names=['first name', 'mail'])
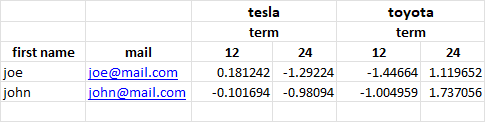
supplement
Removing columns' multi-index names
df4.columns.names = (None,None)
df4.to_excel('test.xlsx', merge_cells=True)