I'm trying to read HTML from the following URL into a pandas dataframe:
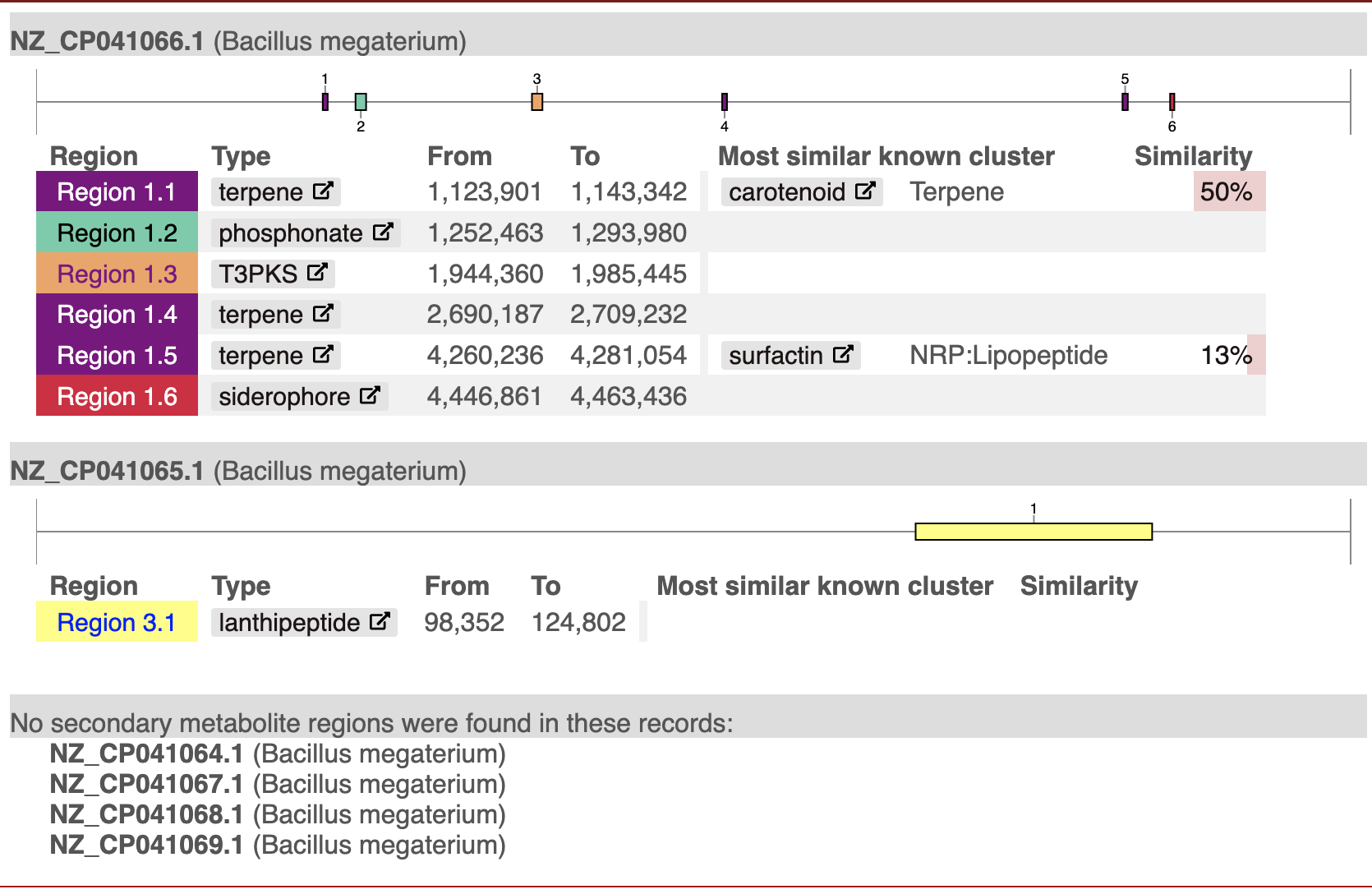
When I read HTML via pandas I get 3 tables. Note, the last table from pd.read_html isn't the "No secondary metabolite" table but a concatenated table of the ones I'm interested in prefixed with "NZ_" in the header.
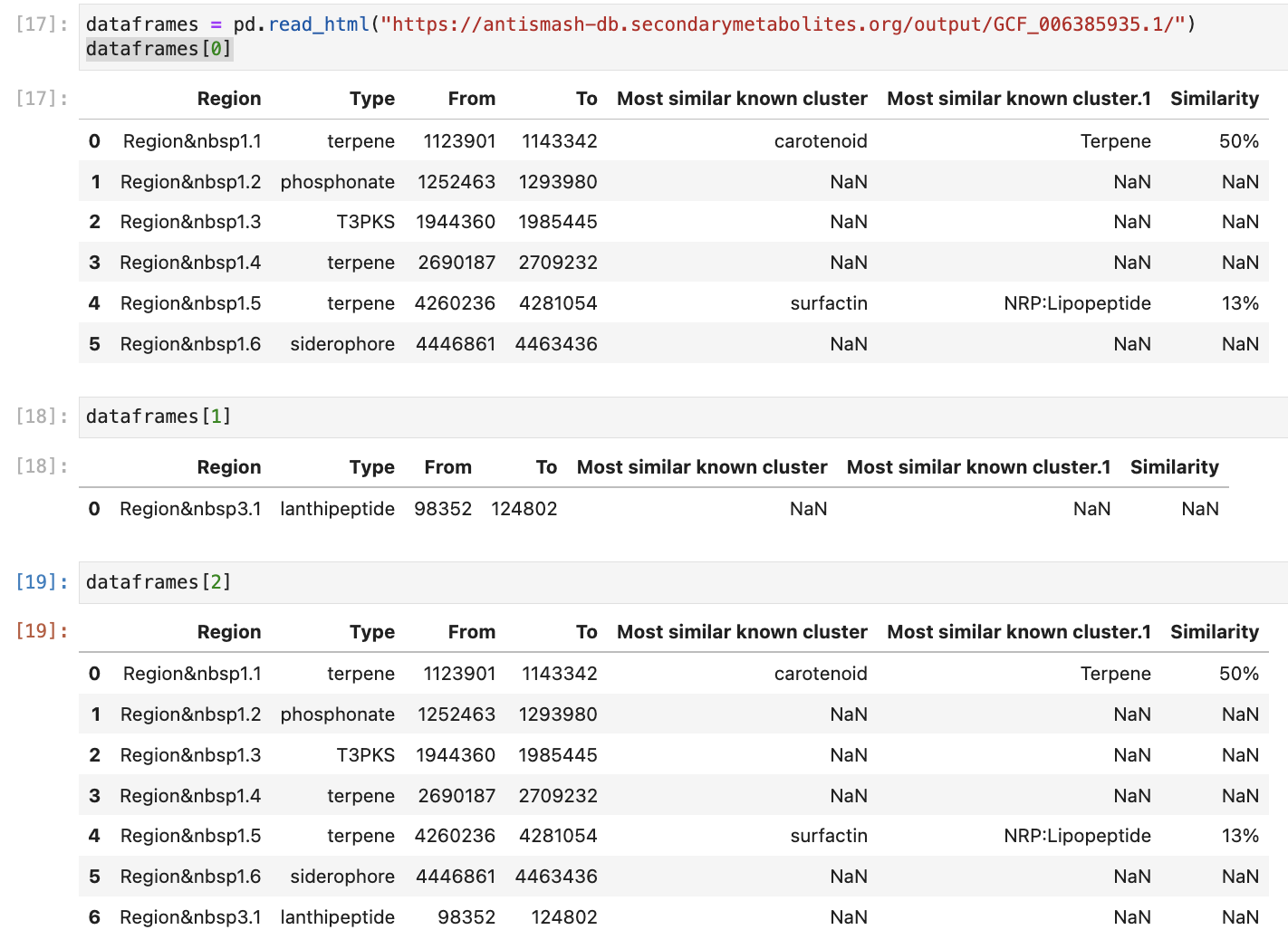
My question is if there is a way to include the headers of the rendered table as a multiindex?
For instance, I'm looking for a resulting table that looks like this:
# Read HTML Tables
dataframes = pd.read_html("https://antismash-db.secondarymetabolites.org/output/GCF_006385935.1/")
# Set Region as the index
dataframes = list(map(lambda df: df.set_index("Region"), dataframes))
# Manual prepending of title and table headers, respectively
dataframes[0].index = dataframes[0].index.map(lambda x: ("GCF_006385935.1", "NZ_CP041066.1", x))
dataframes[1].index = dataframes[1].index.map(lambda x: ("GCF_006385935.1", "NZ_CP041065.1", x))
# Concatenate tables
df_concat = pd.concat(dataframes[:-1], axis=0)
# Replace   characters with _
df_concat.index = df_concat.index.map(lambda x: (x[0], x[1], x[2].replace(" ","_")))
# Multiindex labels
df_concat.index.names = ["level_0", "level_1", "level_2"]
df_concat
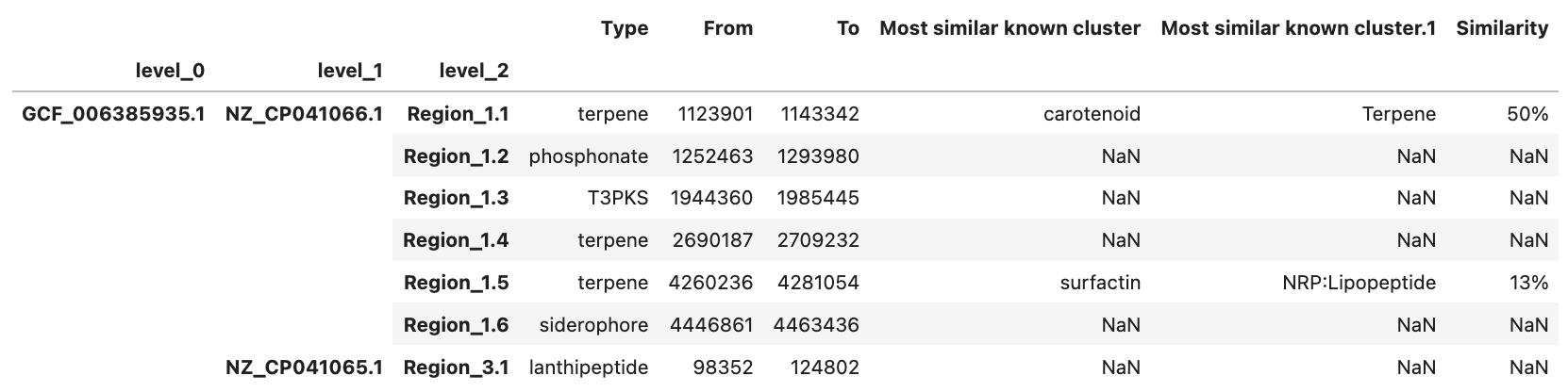
CodePudding user response:
Try beautifulsoup to parse the HTML and construct the final dataframe:
import requests
import pandas as pd
from bs4 import BeautifulSoup
id_ = "GCF_006385935.1"
url = f"https://antismash-db.secondarymetabolites.org/output/{id_}/"
soup = BeautifulSoup(requests.get(url).content, "html.parser")
dfs = []
for table in soup.select(".record-overview-details table"):
header = table.find_previous(class_="record-overview-header").text.split()[
0
]
df = pd.read_html(str(table))[0].assign(level_1=header, level_0=id_)
dfs.append(df)
final_df = pd.concat(dfs)
final_df = final_df.set_index(["level_0", "level_1", "Region"])
print(final_df)
Prints:
Type From To Most similar known cluster Most similar known cluster.1 Similarity
level_0 level_1 Region
GCF_006385935.1 NZ_CP041066.1 Region 1.1 terpene 1123901 1143342 carotenoid Terpene 50%
Region 1.2 phosphonate 1252463 1293980 NaN NaN NaN
Region 1.3 T3PKS 1944360 1985445 NaN NaN NaN
Region 1.4 terpene 2690187 2709232 NaN NaN NaN
Region 1.5 terpene 4260236 4281054 surfactin NRP:Lipopeptide 13%
Region 1.6 siderophore 4446861 4463436 NaN NaN NaN
NZ_CP041065.1 Region 3.1 lanthipeptide 98352 124802 NaN NaN NaN