I have a dataset which looks something like this
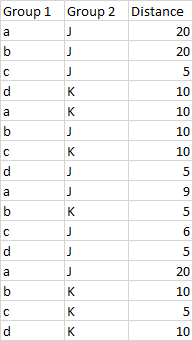
I want to add a column in r that shows the frequency of each Distance value, while still considering the Groups
Ie., I want to change my dataset so that for example like this
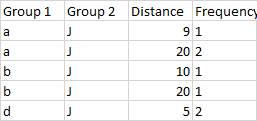
Just wondering what the best way to do this is
CodePudding user response:
dummy data:
df<-data.frame(Group1=c("a","b","c","d","a"),Group2=c("j","k","j","k","j"),Distance=c(20,5,9,10,20))
df<-df[sample(1:nrow(df), 30, replace = TRUE),]
data:
Group1 Group2 Distance
c j 9
c j 9
c j 9
b k 5
b k 5
a j 20
b k 5
c j 9
a j 20
a j 20
df%>%group_by(Group1,Group2,Distance)%>%summarise(Frequency=n())
output:
Group1 Group2 Distance Frequency
<chr> <chr> <dbl> <int>
1 a j 20 3
2 b k 5 3
3 c j 9 4
CodePudding user response:
Here is another solution using tally():
library(tidyverse)
df <- data.frame(Group1 = c("a","b","c","d","a","a","a","a"),
Group2 = c("J","J","J","K","K","J","K","J"),
Distance = c(20,20,5,10,10,10,10,10))
output <- df %>%
group_by(Group1, Group2, Distance) %>%
tally()
The output:
# A tibble: 6 × 4
# Groups: Group1, Group2 [5]
Group1 Group2 Distance n
<chr> <chr> <dbl> <int>
1 a J 10 2
2 a J 20 1
3 a K 10 2
4 b J 20 1
5 c J 5 1
6 d K 10 1