mean_math mean_read mean_science country
1 -4.1976624 30.971633 -1.9381413 AUS
2 -4.0193006 30.542376 8.7161472 CAN
3 -21.8172403 9.638434 -14.6299379 COL
4 -8.6399967 25.467815 -0.6883553 DEU
5 5.4746023 53.493446 22.4550453 FIN
6 -0.0951738 39.918658 12.1398932 GRC
7 14.1162251 27.930612 8.2923826 IDN
8 6.4402359 45.649534 17.5006916 ISR
9 -6.4779173 20.323509 -8.1990175 KOR
10 -1.0302412 26.280249 11.1133112 MAR
11 7.5553361 25.145138 6.7470357 MYS
12 0.1138526 30.203776 8.6622651 NLD
13 -0.7025857 32.751286 -0.4696149 POL
14 21.4963288 64.712999 41.3613420 QAT
15 -5.9149028 22.572479 -2.8969491 SGP
Dataframe diff looks like the result above.
diff %>%
tidyr::pivot_longer(-country) %>%
ggplot(aes(value, country, color = value > 0))
geom_point()
labs(x = "diff", y = "country", colour = "diff > 0")
facet_wrap(~name, scales = "free_x")
coord_cartesian(xlim = c( -100, 100))
This code above is what I've done. and the result is the graph below.
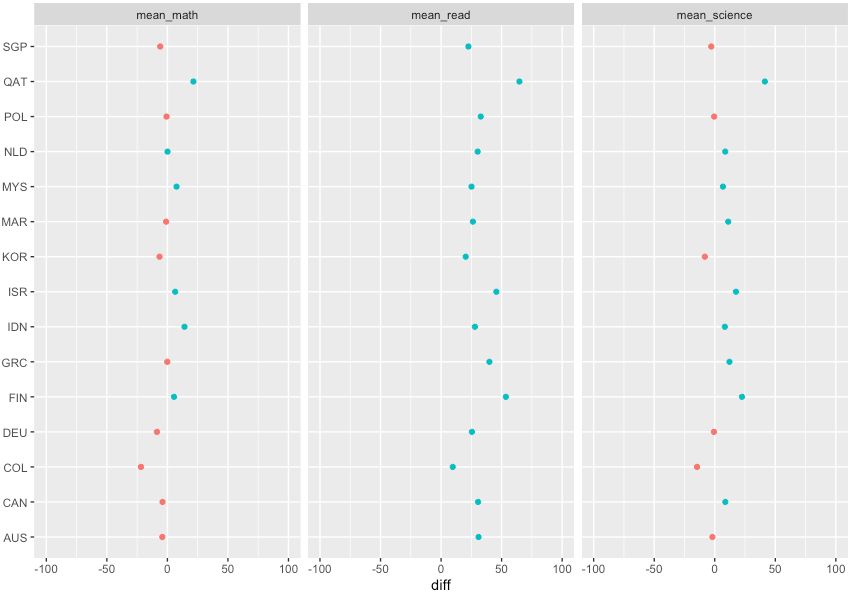
I'd like like to add some codes to make my graph to like this below
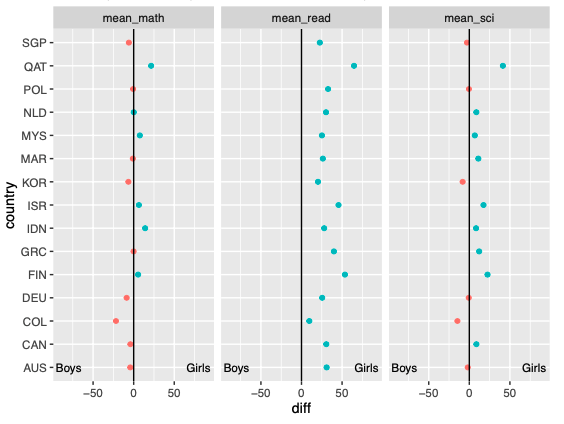
I'd like to put lines on each graph like "result2" graph. ---> (sorted out)
Also for x_scale, how can I remove -100, 100.
Thanks
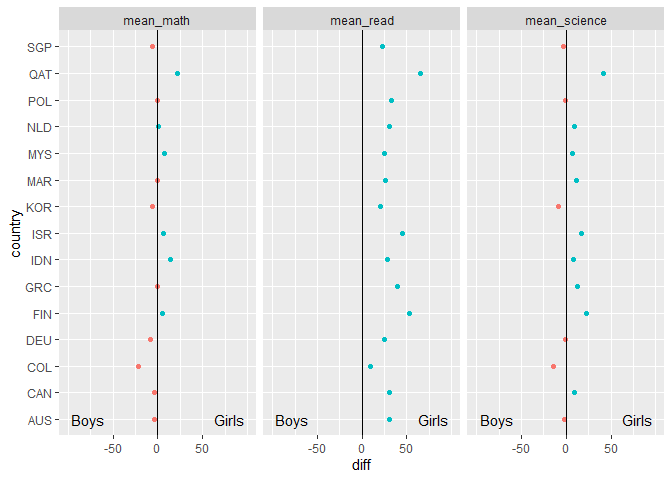
CodePudding user response:
library(tidyr)
library(ggplot2)
diff %>%
tidyr::pivot_longer(-country) %>%
ggplot(aes(value, country, color = value > 0))
geom_point()
labs(x = "diff",
y = "country",
colour = "diff > 0")
geom_vline(xintercept= 0)
scale_x_continuous(breaks = c(-50, 0, 50))
annotate("text", x = -100, y = 1, label = "Boys", hjust = -0.1)
annotate("text", x = 100, y = 1, label = "Girls", hjust = 1.1)
facet_wrap(~name, scales = "free_x")
coord_cartesian(xlim = c( -100, 100))
theme(legend.position = "none")
data
diff <- data.frame(mean_math = c(-4.1976624, -4.0193006, -21.8172403,
-8.6399967, 5.4746023, -0.0951738, 14.1162251, 6.4402359, -6.4779173,
-1.0302412, 7.5553361, 0.1138526, -0.7025857, 21.4963288, -5.9149028),
mean_read = c(30.971633, 30.542376, 9.638434, 25.467815, 53.493446,
39.918658, 27.930612, 45.649534, 20.323509, 26.280249, 25.145138,
30.203776, 32.751286, 64.712999, 22.572479),
mean_science = c(-1.9381413, 8.7161472, -14.6299379, -0.6883553, 22.4550453, 12.1398932, 8.2923826,
17.5006916, -8.1990175, 11.1133112, 6.7470357, 8.6622651, -0.4696149,
41.361342, -2.8969491),
country = c("AUS", "CAN", "COL", "DEU","FIN", "GRC", "IDN",
"ISR", "KOR", "MAR", "MYS", "NLD", "POL", "QAT", "SGP"))
Created on 2022-09-28 with reprex v2.0.2