I have a outer/inner loop-based function I'm trying to vectorise using Python Polars DataFrames. The function is a type of moving average and will be used to filter time-series financial data. Here's the function:
def ma_j(df_src: pl.DataFrame, depth: float):
jrc04 = 0.0
jrc05 = 0.0
jrc06 = 0.0
jrc08 = 0.0
series = df_src['close']
for x in range(0, len(series)):
if x >= x - depth*2:
for k in np.arange(start=math.ceil(depth), stop=0, step=-1):
jrc04 = jrc04 abs(series[x-k] - series[x-(k 1)])
jrc05 = jrc05 (depth k) * abs(series[x-k] - series[x-(k 1)])
jrc06 = jrc06 series[x-(k 1)]
else:
jrc03 = abs(series - (series[1]))
jrc13 = abs(series[x-depth] - series[x - (depth 1)])
jrc04 = jrc04 - jrc13 jrc03
jrc05 = jrc05 - jrc04 jrc03 * depth
jrc06 = jrc06 - series[x - (depth 1)] series[x-1]
jrc08 = abs(depth * series[x] - jrc06)
if jrc05 == 0.0:
ma = 0.0
else:
ma = jrc08/jrc05
return ma
The tricky bit for me are multiple the inner loop look-backs (for k in...). I've looked through multiple examples that use groupby_dynamic on the timeseries data. For example, 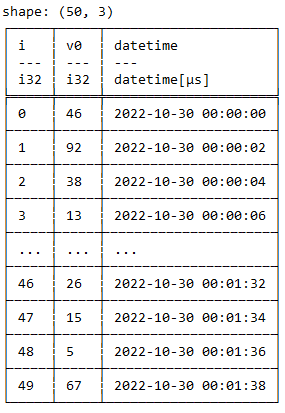
...I can do a grouping by datetime like this":
df.groupby_dynamic("datetime", every="10s").agg([
pl.col("v0").mean().alias('rolling mean')
])
which gives this:
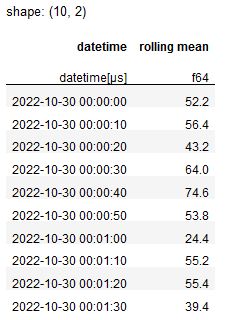
But there's 3 issues with this:
- I don't want to group of datetime...I want to group on every row (maybe
i?) in bins of [x] size. - I need values against every row
- I would like to define the aggregation function, as per the various cases in the function above
Any tips on how I could attack this using Polars? Thanks.
CodePudding user response:
Are you searching for periods="10i"? Polars groupby_rolling accepts a period argument with the following query language:
- 1ns (1 nanosecond)
- 1us (1 microsecond)
- 1ms (1 millisecond)
- 1s (1 second)
- 1m (1 minute)
- 1h (1 hour)
- 1d (1 day)
- 1w (1 week)
- 1mo (1 calendar month)
- 1y (1 calendar year)
- 1i (1 index count)
Where i is simply the number of indices/rows.
So on your data a rolling groupby where we count the number of slots would give:
(df.groupby_rolling(index_column="i", period="10i")
.agg([
pl.count().alias("rolling_slots")
])
)
run GroupbyRollingExec
shape: (50, 2)
┌─────┬───────────────┐
│ i ┆ rolling_slots │
│ --- ┆ --- │
│ i64 ┆ u32 │
╞═════╪═══════════════╡
│ 0 ┆ 1 │
│ 1 ┆ 2 │
│ 2 ┆ 3 │
│ 3 ┆ 4 │
│ ... ┆ ... │
│ 46 ┆ 10 │
│ 47 ┆ 10 │
│ 48 ┆ 10 │
│ 49 ┆ 10 │
└─────┴───────────────┘
CodePudding user response:
def ma_j(df_src: pl.DataFrame, depth: float):
jrc04 = 0.0
jrc05 = 0.0
jrc06 = 0.0
jrc08 = 0.0
series = df_src['close']
for x in range(0, len(series)):
if x >= x - depth*2:
for k in np.arange(start=math.ceil(depth), stop=0, step=-1):
jrc04 = jrc04 abs(series[x-k] - series[x-(k 1)])
jrc05 = jrc05 (depth k) * abs(series[x-k] - series[x-(k 1)])
jrc06 = jrc06 series[x-(k 1)]
else:
jrc03 = abs(series - (series[1]))
jrc13 = abs(series[x-depth] - series[x - (depth 1)])
jrc04 = jrc04 - jrc13 jrc03
jrc05 = jrc05 - jrc04 jrc03 * depth
jrc06 = jrc06 - series[x - (depth 1)] series[x-1]
jrc08 = abs(depth * series[x] - jrc06)
if jrc05 == 0.0:
ma = 0.0
else:
ma = jrc08/jrc05
return ma