I have a data frame loaded in R and I need to calculate mean for each voivodeship for each year. The problem is that I've tried to use rowMeans() function, but the final result is not correct. I also tried a for loop to calculate mean for each year, but I received an error :(
I need a mean using formula for each year (2006 - 2018): gospodarstwa.ogółem.powierzchnia.użytków.rolnych.2006..ha. / gospodarstwa.ogółem.gospodarstwa.2006....
My data:
structure(list(Kod = c(0L, 200000L, 400000L, 600000L, 800000L,
1000000L), Nazwa = c("POLSKA", "DOLNOŚLĄSKIE", "KUJAWSKO-POMORSKIE",
"LUBELSKIE", "LUBUSKIE", "ŁÓDZKIE"),
gospodarstwa.ogółem.gospodarstwa.2006.... = c(9187L, 481L, 173L,
1072L, 256L, 218L), gospodarstwa.ogółem.gospodarstwa.2007.... =
c(11870L, 652L, 217L, 1402L, 361L, 261L),
gospodarstwa.ogółem.gospodarstwa.2008.... = c(14896L, 879L, 258L,
1566L, 480L, 314L), gospodarstwa.ogółem.gospodarstwa.2009.... =
c(17091L, 1021L, 279L, 1710L, 579L, 366L),
gospodarstwa.ogółem.gospodarstwa.2010.... = c(20582L, 1227L, 327L,
1962L, 833L, 420L), gospodarstwa.ogółem.gospodarstwa.2011.... =
c(23449L, 1322L, 371L, 2065L, 1081L, 478L),
gospodarstwa.ogółem.gospodarstwa.2012.... = c(25944L, 1312L, 390L,
2174L, 1356L, 518L), gospodarstwa.ogółem.gospodarstwa.2013.... =
c(26598L, 1189L, 415L, 2129L, 1422L, 528L),
gospodarstwa.ogółem.gospodarstwa.2014.... = c(24829L, 1046L, 401L,
1975L, 1370L, 508L), gospodarstwa.ogółem.gospodarstwa.2015.... =
c(22277L, 849L, 363L, 1825L, 1202L, 478L),
gospodarstwa.ogółem.gospodarstwa.2016.... = c(22435L, 813L, 470L,
1980L, 1148L, 497L), gospodarstwa.ogółem.gospodarstwa.2017.... =
c(20257L, 741L, 419L, 1904L, 948L, 477L),
gospodarstwa.ogółem.gospodarstwa.2018.... = c(19207L, 713L, 395L,
1948L, 877L, 491L),
gospodarstwa.ogółem.powierzchnia.użytków.rolnych.2006..ha. =
c(228038L, 19332L, 4846L, 19957L, 12094L, 3378L),
gospodarstwa.ogółem.powierzchnia.użytków.rolnych.2007..ha. =
c(287529L, 21988L, 5884L, 23934L, 18201L, 3561L),
gospodarstwa.ogółem.powierzchnia.użytków.rolnych.2008..ha. =
c(314848L, 28467L, 5943L, 26892L, 18207L, 4829L),
gospodarstwa.ogółem.powierzchnia.użytków.rolnych.2009..ha. =
c(367062L, 26427L, 6826L, 30113L, 22929L, 5270L),
gospodarstwa.ogółem.powierzchnia.użytków.rolnych.2010..ha. =
c(519069L, 39703L, 7688L, 34855L, 35797L, 7671L),
gospodarstwa.ogółem.powierzchnia.użytków.rolnych.2011..ha. =
c(605520L, 45547L, 8376L, 34837L, 44259L, 8746L),
gospodarstwa.ogółem.powierzchnia.użytków.rolnych.2012..ha. =
c(661688L, 44304L, 8813L, 37466L, 52581L, 9908L),
gospodarstwa.ogółem.powierzchnia.użytków.rolnych.2013..ha. =
c(669970L, 37455L, 11152L, 40819L, 54692L, 10342L),
gospodarstwa.ogółem.powierzchnia.użytków.rolnych.2014..ha. =
c(657902L, 37005L, 11573L, 38467L, 53300L, 11229L),
gospodarstwa.ogółem.powierzchnia.użytków.rolnych.2015..ha. =
c(580730L, 31261L, 10645L, 34052L, 46343L, 10158L),
gospodarstwa.ogółem.powierzchnia.użytków.rolnych.2016..ha. =
c(536579L, 29200L, 9263L, 31343L, 43235L, 9986L),
gospodarstwa.ogółem.powierzchnia.użytków.rolnych.2017..ha. =
c(494978L, 27542L, 8331L, 29001L, 37923L, 9260L),
gospodarstwa.ogółem.powierzchnia.użytków.rolnych.2018..ha. =
c(484677L, 27357L, 7655L, 28428L, 37174L, 8905L), X = c(NA, NA, NA,
NA, NA, NA)), row.names = c(NA, 6L), class = "data.frame")
My attempt:
rowMeans(dane_csv[sapply(dane_csv, is.numeric)])
Final layout (calculated in Excel):
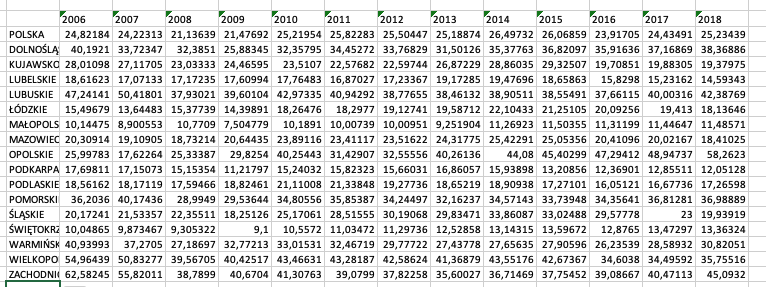
CodePudding user response:
If I understood your problem - the following is a possible tidyverse solution, which uses 3 packages of it:
library(dplyr)
library(stringr)
library(tidyr)
Please make sure to read the documentation on pivoting!
df %>%
# make data "long", excluding ID columns (not sure what "Kod" is you might remove it)
tidyr::pivot_longer(-c(Kod, Nazwa), names_to = "NMS", values_to = "VALS") %>%
# use regex to get what we need from the before column names
# to get the year extract the first 4 digit number
dplyr::mutate(YEAR = stringr::str_extract(NMS, pattern = "\\d{4}"),
# detect if names contains 4 points "." to assign binary value
# I am working arround using TRUE and FALSE as column names even for an intermediary column
# possibly you have no problem with this and might therefore remove the ifelse() call leaving just the the stringr::str_detect() part
DET = ifelse(stringr::str_detect(NMS, pattern = "\\.{4}"), "LOWER", "UPPER")) %>%
# now spread the data again to get the column to devide by in one line
tidyr::pivot_wider(-NMS, names_from = DET, values_from = VALS) %>%
# perform needed calulation between columsn
dplyr::mutate(DIF = UPPER/LOWER) %>%
# remove NA rows to prevent "empty columns
dplyr::filter(!is.na(DIF)) %>%
# make the data wide again, while removing the two intermediary columns
tidyr::pivot_wider(-c(LOWER, UPPER), names_from = "YEAR", values_from = "DIF")
# A tibble: 6 x 16
Kod Nazwa `2006` `2007` `2008` `2009` `2010` `2011` `2012` `2013` `2014` `2015` `2016` `2017` `2018`
<int> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 0 POLSKA 24.8 24.2 21.1 21.5 25.2 25.8 25.5 25.2 26.5 26.1 23.9 24.4 25.2
2 200000 DOLNOSLASKIE 40.2 33.7 32.4 25.9 32.4 34.5 33.8 31.5 35.4 36.8 35.9 37.2 38.4
3 400000 KUJAWSKO-POMORSKIE 28.0 27.1 23.0 24.5 23.5 22.6 22.6 26.9 28.9 29.3 19.7 19.9 19.4
4 600000 LUBELSKIE 18.6 17.1 17.2 17.6 17.8 16.9 17.2 19.2 19.5 18.7 15.8 15.2 14.6
5 800000 LUBUSKIE 47.2 50.4 37.9 39.6 43.0 40.9 38.8 38.5 38.9 38.6 37.7 40.0 42.4
6 1000000 LÓDZKIE 15.5 13.6 15.4 14.4 18.3 18.3 19.1 19.6 22.1 21.3 20.1 19.4 18.1
CodePudding user response:
Base R solution:
# Reshape (unpivot) the data to enable vectorised manipulation:
# reshaped_df => data.frame
reshaped_df <- reshape(
df1,
direction = "long",
varying = names(df1)[!(names(df1) %in% c("Kod", "Nazwa"))],
idvar = "Kod",
timevar = "Metric",
times = names(df1)[!(names(df1) %in% c("Kod", "Nazwa"))],
v.names = "Value",
new.row.names = seq_len(nrow(df1) * length(names(df1)[!(names(df1) %in% c("Kod", "Nazwa"))]))
)
# Feature engineer to derive and standardised vectors:
# transformed_df => data.frame
transformed_df <- transform(
reshaped_df,
Year = as.integer(
gsub(".*\\.(\\d )\\..*", "\\1", Metric)
),
Kod = as.character(Kod),
Numerator = ifelse(
grepl(
"gospodarstwa.ogółem.powierzchnia.użytków.rolnych",
Metric
),
Value,
0L
),
Denominator = ifelse(
grepl(
"gospodarstwa.ogółem.gospodarstwa",
Metric
),
Value,
0L
)
)[,c("Kod", "Nazwa", "Year", "Numerator", "Denominator")]
# Aggregate the data and calculate the mean for a given country
# in a given year: aggregated_df => data.frame
aggregated_df <- transform(
aggregate(
.~Kod Nazwa Year,
transformed_df,
FUN = sum
),
Value = Numerator / Denominator
)[,c("Kod", "Nazwa", "Year", "Value")]
# Pivot the data so each row is a country and each column
# a year: pivotted_df => data.frame
pivotted_df <- as.data.frame.matrix(
xtabs(
Value~Nazwa Year,
aggregated_df
),
stringsAsFactors = FALSE
)
# Order the rows and columns as required:
# formatted_df => data.frame
formatted_df <- setNames(
data.frame(
transform(
pivotted_df,
Nazwa = row.names(pivotted_df)
)[match(df1$Nazwa, row.names(pivotted_df)),c("Nazwa", paste0("X", colnames(pivotted_df)))],
stringsAsFactors = FALSE,
row.names = NULL
),
c("Nazwa", colnames(pivotted_df))
)
# Display result to console:
# data.frame => stdout(console)
formatted_df
Data:
df1 <- structure(list(Kod = c(0L, 200000L, 400000L, 600000L, 800000L,
1000000L), Nazwa = c("POLSKA", "DOLNOŚLĄSKIE", "KUJAWSKO-POMORSKIE",
"LUBELSKIE", "LUBUSKIE", "ŁÓDZKIE"),
gospodarstwa.ogółem.gospodarstwa.2006.... = c(9187L, 481L, 173L,
1072L, 256L, 218L), gospodarstwa.ogółem.gospodarstwa.2007.... =
c(11870L, 652L, 217L, 1402L, 361L, 261L),
gospodarstwa.ogółem.gospodarstwa.2008.... = c(14896L, 879L, 258L,
1566L, 480L, 314L), gospodarstwa.ogółem.gospodarstwa.2009.... =
c(17091L, 1021L, 279L, 1710L, 579L, 366L),
gospodarstwa.ogółem.gospodarstwa.2010.... = c(20582L, 1227L, 327L,
1962L, 833L, 420L), gospodarstwa.ogółem.gospodarstwa.2011.... =
c(23449L, 1322L, 371L, 2065L, 1081L, 478L),
gospodarstwa.ogółem.gospodarstwa.2012.... = c(25944L, 1312L, 390L,
2174L, 1356L, 518L), gospodarstwa.ogółem.gospodarstwa.2013.... =
c(26598L, 1189L, 415L, 2129L, 1422L, 528L),
gospodarstwa.ogółem.gospodarstwa.2014.... = c(24829L, 1046L, 401L,
1975L, 1370L, 508L), gospodarstwa.ogółem.gospodarstwa.2015.... =
c(22277L, 849L, 363L, 1825L, 1202L, 478L),
gospodarstwa.ogółem.gospodarstwa.2016.... = c(22435L, 813L, 470L,
1980L, 1148L, 497L), gospodarstwa.ogółem.gospodarstwa.2017.... =
c(20257L, 741L, 419L, 1904L, 948L, 477L),
gospodarstwa.ogółem.gospodarstwa.2018.... = c(19207L, 713L, 395L,
1948L, 877L, 491L),
gospodarstwa.ogółem.powierzchnia.użytków.rolnych.2006..ha. =
c(228038L, 19332L, 4846L, 19957L, 12094L, 3378L),
gospodarstwa.ogółem.powierzchnia.użytków.rolnych.2007..ha. =
c(287529L, 21988L, 5884L, 23934L, 18201L, 3561L),
gospodarstwa.ogółem.powierzchnia.użytków.rolnych.2008..ha. =
c(314848L, 28467L, 5943L, 26892L, 18207L, 4829L),
gospodarstwa.ogółem.powierzchnia.użytków.rolnych.2009..ha. =
c(367062L, 26427L, 6826L, 30113L, 22929L, 5270L),
gospodarstwa.ogółem.powierzchnia.użytków.rolnych.2010..ha. =
c(519069L, 39703L, 7688L, 34855L, 35797L, 7671L),
gospodarstwa.ogółem.powierzchnia.użytków.rolnych.2011..ha. =
c(605520L, 45547L, 8376L, 34837L, 44259L, 8746L),
gospodarstwa.ogółem.powierzchnia.użytków.rolnych.2012..ha. =
c(661688L, 44304L, 8813L, 37466L, 52581L, 9908L),
gospodarstwa.ogółem.powierzchnia.użytków.rolnych.2013..ha. =
c(669970L, 37455L, 11152L, 40819L, 54692L, 10342L),
gospodarstwa.ogółem.powierzchnia.użytków.rolnych.2014..ha. =
c(657902L, 37005L, 11573L, 38467L, 53300L, 11229L),
gospodarstwa.ogółem.powierzchnia.użytków.rolnych.2015..ha. =
c(580730L, 31261L, 10645L, 34052L, 46343L, 10158L),
gospodarstwa.ogółem.powierzchnia.użytków.rolnych.2016..ha. =
c(536579L, 29200L, 9263L, 31343L, 43235L, 9986L),
gospodarstwa.ogółem.powierzchnia.użytków.rolnych.2017..ha. =
c(494978L, 27542L, 8331L, 29001L, 37923L, 9260L),
gospodarstwa.ogółem.powierzchnia.użytków.rolnych.2018..ha. =
c(484677L, 27357L, 7655L, 28428L, 37174L, 8905L)), row.names = c(NA, 6L), class = "data.frame")