I am trying to filter the data shown below.
df<-data.frame(
Country=c("Aruba","Aruba","Aruba","Afghanistan","Afghanistan","Afghanistan","Afghanistan","Butan","Butan","Belize"),
Year=c("2007","2008","2009","2006","2007","2008","2009","2006","2009","2006"),
Value=c(158,196,NA,156,140,693,854,NA,904,925))
df
I want to filter only the last values from each country with values different from NA. In the end I need to have the result as a result shown below
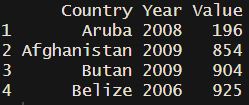
So can anybody help me how to solve this problem?
CodePudding user response:
your_data %>%
na.omit() %>%
group_by(Country) %>%
slice_tail(1) %>%
ungroup()
CodePudding user response:
Base R solution (using Pipes |> so please make sure your R version >= 4.1):
# Split-apply-combine approach mapping ordering and tail functions
# over data.frame split into list of data.frames by country:
# result => data.frame
result <- df[complete.cases(df$Value),] |>
(\(x){
data.frame(
do.call(
rbind,
lapply(
split(
x,
x$Country
),
function(y){
tail(
y[order(y$Year),],
1
)
}
)
),
stringsAsFactors = FALSE,
row.names = NULL
)
}
)()
# Print result to console:
# data.frame => stdout(console)
result