I am trying web scraping with R (rvest) for the first time. I am trying to replace missing values with 'NA' but it doesn't seem to work at all. Can you guys check the code below and please help me?
library(rvest)
library('purrr')
link= "https://www.imdb.com/search/title/?title_type=feature&num_votes=25000,&genres=action&sort=user_rating,desc&start=1&ref_=adv_nxt"
page=read_html(link)
movies<-data.frame(name = page %>% html_nodes(".lister-item-header a") %>% html_text,
year = page %>% html_nodes(".text-muted.unbold") %>% html_text(),
certificate = page %>% html_nodes(".certificate") %>% html_text(),
runtime = page %>% html_nodes(".runtime") %>% html_text(),
genre = page %>% html_nodes(".genre") %>% html_text(),
imdb_rating = page %>% html_nodes(".ratings-imdb-rating strong") %>% html_text(),
director = page %>% html_nodes(".text-muted p a:nth-child(1)") %>% html_text(),
number_of_votes = page %>% html_nodes(".sort-num_votes-visible span:nth-child(2)") %>% html_text(),
gross = page %>% html_nodes(".ghost~ .text-muted span") %>% html_text())
The certificate and gross values are missing for certain movies. I tried the following methods to replace missing values with N/A
certificate = page %>%
html_nodes(".certificate") %>% html_text() %>% gsub('\\s ', ' ', .)
gross = page %>% html_nodes(".ghost~ .text-muted span") %>% html_text() %>% replace(!nzchar(.),NA)
certificate = page %>% html_nodes(".certificate") %>%
html_text(trim = TRUE) %>% {if(length(.) == "") NA else .}
None of them work for me. The commands execute without error but does not replace the missing values with NA and I get less number of entries.
Without replacing the missing values, I cannot make the movies data frame because I get the error as:
error in data.frame(name = page %>% html_nodes(".lister-item-header a") %>% :
arguments imply differing number of rows: 50, 49, 37
CodePudding user response:
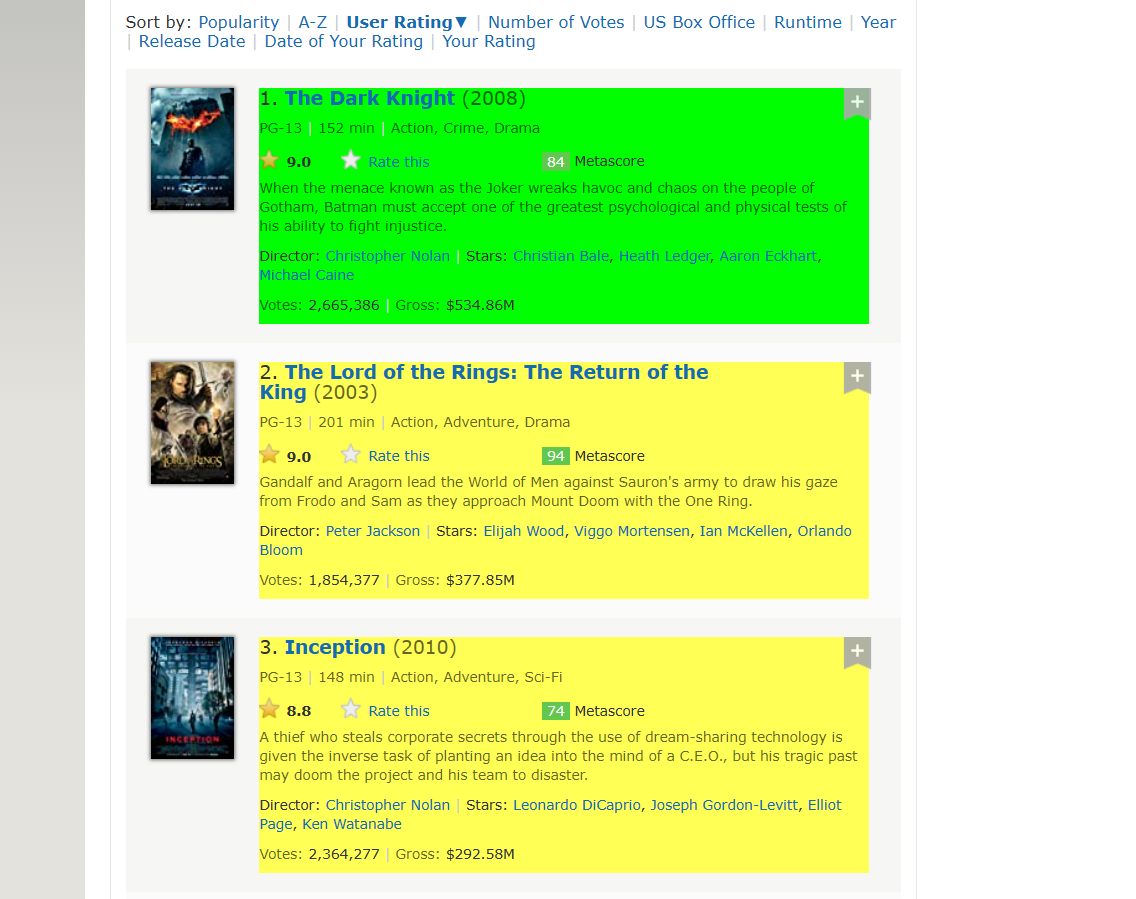
I recommend narrowing your web scraping focus to a specific parent element, such as the cards shown in the image, and then iterating through those elements to extract the specific child elements of interest. This approach will make the process more efficient and targeted. NA will be returned if no element is found in certain cards.
library(tidyverse)
library(rvest)
movies <-
"https://www.imdb.com/search/title/?title_type=feature&num_votes=25000,&genres=action&sort=user_rating,desc&start=1&ref_=adv_nxt" %>%
read_html()
movies %>%
html_elements(".lister-item-content") %>% # the cards
map_dfr(~ tibble( # interate through the list and grab the elements:
title = .x %>%
html_element(".lister-item-header a") %>%
html_text2(),
year = .x %>%
html_element(".text-muted.unbold") %>%
html_text2(),
certificate = .x %>%
html_element(".certificate") %>%
html_text2(),
runtime = .x %>%
html_element(".runtime") %>%
html_text2(),
genre = .x %>%
html_element(".genre") %>%
html_text2(),
rating = .x %>%
html_element(".ratings-imdb-rating strong") %>%
html_text2(),
director = .x %>%
html_element(".text-muted p a:nth-child(1)") %>%
html_text2(),
votes = .x %>%
html_element(".sort-num_votes-visible span:nth-child(2)") %>%
html_text2(),
gross = .x %>%
html_element(".ghost~ .text-muted span") %>%
html_text2()
))
Results
# A tibble: 50 × 9
title year certi…¹ runtime genre rating direc…² votes gross
<chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
1 "The Dark Knight" (200… 15 152 min Acti… 9.0 Christ… 2,66… $534…
2 "Ringenes herre: Atter en kong… (200… 12 201 min Acti… 9.0 Peter … 1,85… $377…
3 "Inception" (201… 15 148 min Acti… 8.8 Christ… 2,36… $292…
4 "Ringenes herre: Ringens brors… (200… 12 178 min Acti… 8.8 Peter … 1,88… $315…
5 "Ringenes herre: To t\u00e5rn" (200… 12 179 min Acti… 8.8 Peter … 1,67… $342…
6 "The Matrix" (199… 15 136 min Acti… 8.7 Lana W… 1,92… $171…
7 "Star Wars: Episode V - Imperi… (198… 9 124 min Acti… 8.7 Irvin … 1,29… $290…
8 "Soorarai Pottru" (202… NA 153 min Acti… 8.7 Sudha … 117,… NA
9 "Stjernekrigen" (197… 11 121 min Acti… 8.6 George… 1,37… $322…
10 "Terminator 2 - Dommens dag" (199… 15 137 min Acti… 8.6 James … 1,10… $204…
# … with 40 more rows, and abbreviated variable names ¹certificate, ²director
# ℹ Use `print(n = ...)` to see more rows