I'm trying to calculate the similarity between two strings in a dataframe, so i've searched and found the levehstein distance which doesn't help me.
In my case the strings are separated by a comma , so i want to calculate the similarity between two columns, and here is an example:
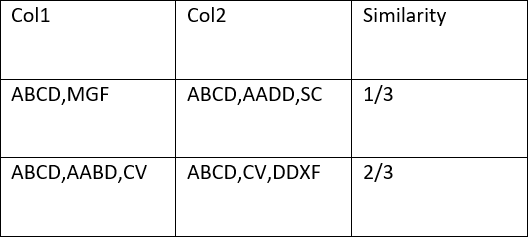
like shown in this image i want to comapre the list of strings of col 1 with the list of strings in col2 and calculate the similarity between them like this : {number of paragraphes in col1 that matches with the ones in col2}/{number of paragraphes in col 2} so please if you can help me , or is there a function to calculate similarity like this ,because i've searched and didn't find anything on this particular case
PS: Knowing that paragraphes are separated by a comma ,
CodePudding user response:
You can use spark inbuilt functions array_intersect,size,split,concat_ws funcitons.
Example:
df.show()
# ------------ ------------
#| Col1| Col2|
# ------------ ------------
#| ABCD,MGF|ABCD,AADD,SC|
#|ABCD,AABD,CV|ABCD,CV,DDXF|
# ------------ ------------
df.withColumn("Similarity",concat_ws("/",size(array_intersect(split(col("col1"),","),split(col("col2"),","))),size(split(col("col2"),",")))).show()
# ------------ ------------ ----------
#| Col1| Col2|Similarity|
# ------------ ------------ ----------
#| ABCD,MGF|ABCD,AADD,SC| 1/3|
#|ABCD,AABD,CV|ABCD,CV,DDXF| 2/3|
# ------------ ------------ ----------