i am using this textbook Randal E. Bryant, David R. O’Hallaron - Computer Systems. A Programmer’s Perspective [3rd ed.] (2016, Pearson), and there is a section I don't really understand very well.
C code:
void write_read(long *src, long *dst, long n)
{
long cnt = n;
long val = 0;
while (cnt) {
*dst = val;
val = (*src) 1;
cnt--;
}
}
Inner loop of write_read:
#src in %rdi, dst in %rsi, val in %rax
.L3:
movq %rax, (%rsi) # Write val to dst
movq (%rdi), %rax # t = *src
addq $1, %rax # val = t 1
subq $1, %rdx # cnt--
jne .L3 # If != 0, goto loop
Given this code, the textbook gives this diagram to describe the program flow 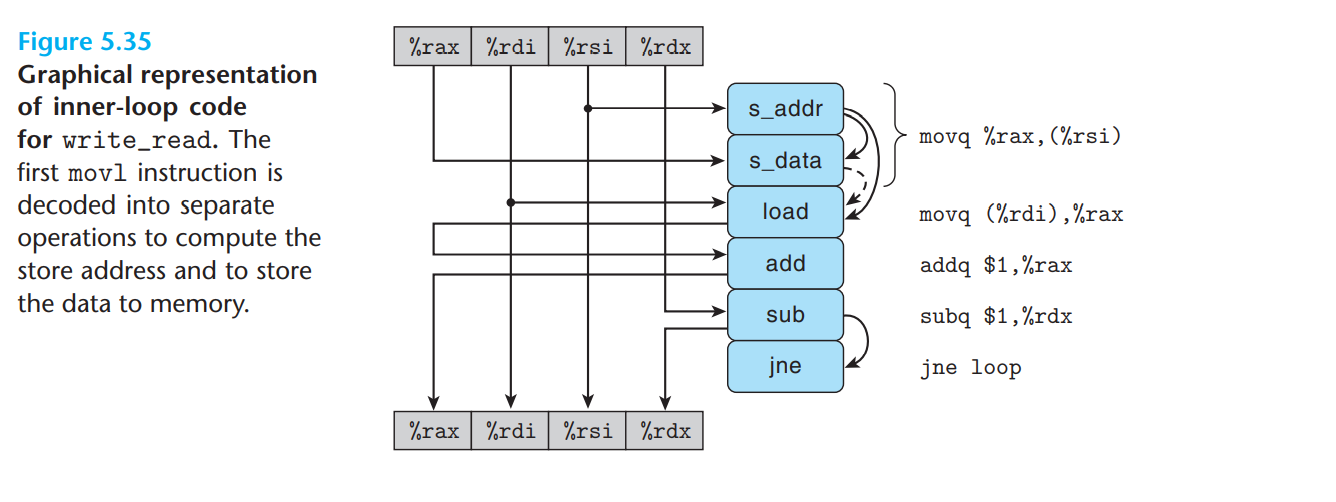
This is the explanation given, for those who don't have access to the TB:
Figure 5.35 shows a data-flow representation of this loop code. The instruction
movq %rax,(%rsi)is translated into two operations: The s_addr instruction computes the address for the store operation, creates an entry in the store buffer, and sets the address field for that entry. The s_data operation sets the data field for the entry. As we will see, the fact that these two computations are performed independently can be important to program performance. This motivates the separate functional units for these operations in the reference machine.In addition to the data dependencies between the operations caused by the writing and reading of registers, the arcs on the right of the operators denote a set of implicit dependencies for these operations. In particular, the address computation of the s_addr operation must clearly precede the s_data operation.
In addition, the load operation generated by decoding the instruction
movq (%rdi), %raxmust check the addresses of any pending store operations, creating a data dependency between it and the s_addr operation. The figure shows a dashed arc between the s_data and load operations. This dependency is conditional: if the two addresses match, the load operation must wait until the s_data has deposited its result into the store buffer, but if the two addresses differ, the two operations can proceed independently.
a) What I am not really clear about is why after this line movq %rax,(%rsi) there needs to be a load done after s_data is called? I'm assuming that when s_data is called, the value of %rax is stored in the location that the address of %rsi is pointing to? Does this mean that after every s_data there needs to be a load call?
b) It doesn't really show in the diagram but from what I understand from the explanation given in the book, movq (%rdi), %rax this line requires its own set of s_addr and s_data? So is it accurate to say that all movq calls require an s_addr and s_data call followed by the check to check if the addresses match before calling load ?
Quite confused over these parts, would appreciate if someone can explain how the s_addr and s_data calls work with load and when it is required to have these functions, thank you!!
CodePudding user response:
The operations in the blue boxes are micro-operations (also called uops or micro-instructions) emitted by the decoders of the pipeline. They are part of the program being executed. The movq (%rdi), %rax instruction is decoded into the load uop. A uop is the unit of execution in the pipeline. Uops aren't called, they're executed.
According to the hypothetical processor design discussed in the book, a simple store instruction like movq %rax, (%rsi) is decoded into two uops, called s_addr and s_data. This happens in real x86 processors as well. One reason why a macro instruction may be decoded into more than one uop is because the format of a uop doesn't allow it to hold all the information given in the instruction, such as when the instruction has too many operands or represents a complex task. Another reason is to increase instruction-level parallelism. The address of the store and the data of the store could become available in different cycles. If the address is available but the data isn't, the s_addr uop can be dispatched to the load-store unit to enable the addresses of downstream load uops be compared earlier against the address of the store without having to wait for the data of the store. The process of determining whether a later load depends on earlier store is called memory disambiguation. If the load movq (%rdi), %rax doesn't overlap with the earlier store movq %rax, (%rsi), then it can be executed immediately, irrespective of whether the value in %rax is ready or not.
When the s_data uop is executed, the value in %rax is stored in the data field of the store buffer entry in which the store uop was allocated. Storing the value in the target memory location happens later, after all earlier instructions complete execution to maintain program order.
The book says that "the address computation of the s_addr operation must clearly precede the s_data operation" probably because, according to the book, the s_addr uop has to first create an entry in the store buffer before the data can be stored in it. This may be fine for the hypothetical design, but it's an unnecessary dependency since allocation can be done before execution. Resource allocation and reclamation isn't discussed in the book anyway.
A simple load instruction is decoded into a single load uop. There is no reason to split the load into multiple uops.