i have dataframe like picture:
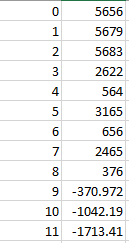
and I have index list:
index = ["A", "B","C"]
I want every 3 rows this index repeat like picture:
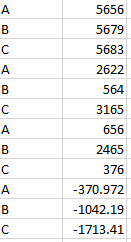
Is there a efficient way to do it? Thanks!
CodePudding user response:
You can use this trick:
df.index = (df.index % 3 65).map(chr)
print(df)
# Output
0
A 0.410769
B 0.588686
C 0.173944
A 0.911229
B 0.424803
C 0.671895
A 0.665640
B 0.071965
C 0.050997
A 0.965870
B 0.119070
C 0.230928
In ASCII, 'A' has the value 65, 'B' 66, 'C' 67 and so on...
If you want to use your index, use:
# Enhanced by @mozway
df.index = (df.index % len(index)).map(dict(enumerate(index)))
print(df)
# Output
0
A 0.410769
B 0.588686
C 0.173944
A 0.911229
B 0.424803
C 0.671895
A 0.665640
B 0.071965
C 0.050997
A 0.965870
B 0.119070
C 0.230928
With this solution, the length of your index list or the dataframe doesn't matter.
CodePudding user response:
You can extend the list to the desired length then use pandas.Dataframe.reindex:
https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.reindex.html
CodePudding user response:
Since you didn't provide a reproducible example of your problem, I have generated a random list and assigned them to the dataframe, but the approach to the solution will be the same.
If you are sure about the number of elements in the first column (12) you can try:
import random
import pandas as pd
values = random.sample(range(6000, 8000), 12) # Random list, you won't need this line
df = pd.DataFrame({"values": values})
alphabets = ["A", "B", "C"] * 4
df["new_column"] = alphabets
df
If not, you can follow code below:
import random
import pandas as pd
values = random.sample(range(6000, 8000), 12) # Random list, you won't need this line
df = pd.DataFrame({"values": values})
alphabets = ["A", "B", "C"]
newColumn = []
for index, row in df.iterrows():
newColumn.append(alphabets[index%3])
df["new_column"] = newColumn
df
In either cases, you will have the following result:
| values | new_column | |
|---|---|---|
| 0 | 7384 | A |
| 1 | 7014 | B |
| 2 | 6997 | C |
| 3 | 6266 | A |
| 4 | 6552 | B |
| 5 | 6568 | C |
| 6 | 7907 | A |
| 7 | 6209 | B |
| 8 | 7475 | C |
| 9 | 7817 | A |
| 10 | 6293 | B |
| 11 | 6218 | C |